-
Ensemble LearningAI 2026. 1. 27. 08:57
데이터 사이언스 경진대회인 캐글(Kaggle) 상위권 솔루션을 보면 빠지지 않고 등장하는 단어가 있습니다. 바로 '앙상블(Ensemble)'입니다. 딥러닝이 비정형 데이터(이미지, 영상)를 지배한다면, 정형 데이터(표 데이터)의 왕은 여전히 앙상블 기법입니다.
앙상블 학습은 여러 개의 머신러닝 모델(Weak Learner)을 결합하여, 하나의 모델만 사용할 때보다 더 정확하고 신뢰성 높은 예측 결과를 도출하는 기법입니다.
한 명의 천재(강력한 단일 모델)가 모든 문제를 해결할 수도 있지만, 평범한 여러 사람(약한 모델)이 모여 투표하거나 의견을 종합했을 때 더 안정적이고 뛰어난 결과를 내는 '집단 지성'의 원리를 머신러닝에 적용한 것입니다.
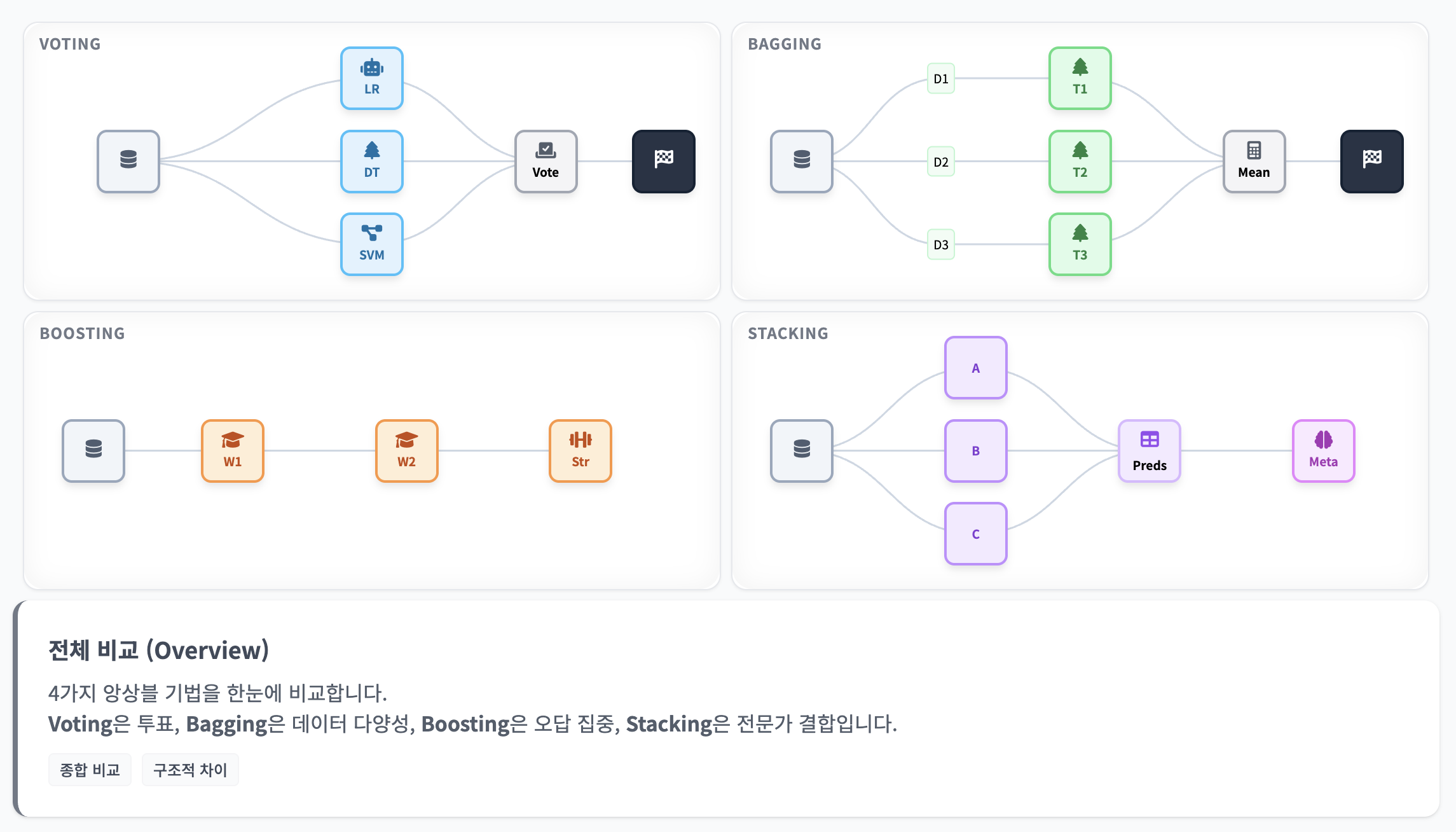
오늘은 여러 모델을 조합하여 강력한 성능을 내는 앙상블 학습의 핵심 개념과 대표적인 4가지 기법(Voting, Bagging, Boosting, Stacking)을 정리해보겠습니다.
보팅 (Voting) - 투표를 통한 결정
가장 직관적인 방식입니다. '서로 다른 알고리즘'을 가진 모델들이 투표를 통해 최종 결과를 결정합니다.
- 특징: 선형회귀, SVM, 결정트리 등 다양한 모델이 같은 데이터를 보고 판단합니다.
- 유형:
- 하드 보팅 (Hard Voting): 다수결 원칙. 가장 많은 표를 받은 예측값을 선택합니다.
- 소프트 보팅 (Soft Voting): 각 모델이 예측한 확률(Probability)의 평균을 냅니다. 정보 손실이 적어 성능이 더 좋습니다.
- 가중치 보팅 (Weighted Voting): 실전 팁! 모든 모델을 똑같이 신뢰하지 않고, 성능이 좋은 모델에 더 큰 투표권(가중치)을 줍니다.
"그저 여러 모델을 합친다고 정말 성능이 좋아질까?"라고 의문을 가질 수 있습니다. 이를 증명하기 위해 우주 통신에서의 에러 수정(Error Correction) 원리와 확률 계산을 예로 들어보겠습니다.
우주 통신과 에러 수정 (Repetition Code)
우주 임무에서는 신호(Signal) 하나가 생명을 좌우할 수 있습니다. 만약 우리가 받은 이진 신호가 다음과 같다고 가정해 봅시다.
Original Signal: 1110110011
그런데 전송 과정에서 잡음이 섞여 두 번째 자리의 '1'이 '0'으로 변질되었다면 어떻게 될까요?
Corrupted Signal: 1010110011 (두 번째 비트 오류!)
치명적인 사고를 막기 위해 반복 코드(Repetition Code) 기법을 사용합니다. 신호를 여러 번 반복해서 보내고, 수신 측에서 다수결 투표(Majority Vote)를 하는 것입니다.
- 인코딩 (3번 반복 전송): 1010110011 (원본 손상) 1110110011 (정상) 1110110011 (정상)
- 다수결 투표 (Majority Vote): 세 개의 신호를 세로로 비교했을 때, 두 번째 자리에서 0, 1, 1이 나왔으므로 다수결에 의해 1로 판단합니다.
Result: 1110110011 (복구 완료!)
이처럼 다수결 원칙은 개별 신호의 오류를 효과적으로 수정해 줍니다. 머신러닝의 앙상블도 이와 똑같은 원리로 작동합니다.
머신러닝에서의 확률적 증명
이를 머신러닝 모델의 정확도로 계산해 보겠습니다.
- 상황: 정답이 모두 1인 샘플 10개가 있습니다. 1111111111
- 모델: 정확도가 70%인(조금 똑똑한 난수 생성기 수준의) 분류기 3개를 준비합니다.
이 3명의 분류기가 다수결 투표를 할 때, 과연 정확도는 70%에 머물러 있을까요? 수학적으로 계산해 보면 놀라운 결과가 나옵니다.
- 3개 모두 정답일 확률: $0.7 \times 0.7 \times 0.7 = 0.343$
- 2개만 정답일 확률 (이 경우도 다수결로 정답 처리됨): $(0.7 \times 0.7 \times 0.3) + (0.7 \times 0.3 \times 0.7) + (0.3 \times 0.7 \times 0.7) = 0.441$
Voting결과에 따라서 1개만 정답일 확률과 모두 오답일 확률은 제외한다. 그래서, 이 두 경우를 합치면 앙상블 모델의 최종 정확도가 됩니다.
최종 정확도: $0.343 + 0.441 =$ 약 78.4%
개별 모델은 70%의 성능밖에 내지 못했지만, 단 3개를 모아 다수결 투표를 진행했을 뿐인데 정확도가 8.4%나 상승했습니다. 모델의 개수가 늘어날수록 이 정확도는 더 드라마틱하게 올라갑니다.
이것이 바로 약한 학습기(Weak Learner)를 모아 강한 학습기(Strong Learner)를 만드는 앙상블의 마법입니다.
왜 '가중치'가 중요할까?
기본적인 소프트 보팅은 모든 모델의 의견을 1/N로 똑같이 반영합니다. 하지만, 전교 1등과 전교 꼴찌의 정답을 똑같은 비중으로 믿는 것은 비합리적일 수 있습니다.
- 단순 평균 (Unweighted): (모델A + 모델B + 모델C) ÷ 3
- 가중치 적용 (Weighted): (모델A × 0.5) + (모델B × 0.3) + (모델C × 0.2)
배깅 (Bagging): 따로 또 같이
Bootstrap Aggregating의 줄임말입니다. 보팅과 달리 '같은 알고리즘'을 사용하지만, 학습 데이터를 다르게 사용하는 것이 핵심입니다.
- 특징:
- Bootstrap: 전체 데이터에서 중복을 허용하여 랜덤하게 샘플을 추출합니다.
- Aggregation: 각 데이터로 학습한 모델들의 결과를 합칩니다(분류는 투표, 회귀는 평균).
- 장점: 병렬 처리가 가능해 빠르며, 모델의 분산(Variance)을 줄여 과적합(Overfitting) 방지에 탁월합니다.
- 대표 모델: 랜덤 포레스트 (Random Forest)
❓ 잠깐! 보팅과 배깅이 헷갈린다면?
- Voting: 서로 다른 모델 + 같은 데이터 (수학자, 과학자, 문학가의 회의)
- Bagging: 같은 모델 + 다른 데이터 (수학자 100명이 서로 다른 문제집 풀기)
- 참고: 배깅의 마지막 취합 과정에서 투표(Voting) 방식을 사용하지만, 전략 자체가 다릅니다.
부스팅 (Boosting): 오답 노트 학습법
부스팅은 순차적(Sequential)인 과정입니다. 이전 모델이 틀린 문제(오차)에 가중치를 두어 다음 모델이 집중적으로 학습하게 하는 방식입니다.
- 핵심 개념: "약한 모델(Weak Learner) 여러 개를 순서대로 연결하여 강한 모델을 만든다."
- 비유: 수학 문제집을 풉니다.
- 처음에 1번부터 100번까지 풉니다.
- 채점을 하고 틀린 문제만 모아 다시 공부합니다. (가중치 부여)
- 틀린 문제 위주로 다시 시험을 봅니다.
- 그래도 또 틀린 문제는 더 집중해서 봅니다.
- 이 과정을 반복하여 최종 실력을 완성합니다.
- 작동 원리:
- 첫 번째 모델이 예측을 수행합니다.
- 예측이 틀린 데이터에 가중치(Weight)를 높입니다.
- 두 번째 모델은 가중치가 높은(이전 모델이 틀린) 데이터를 더 잘 맞추도록 학습합니다.
- 이 과정을 반복한 뒤, 모든 모델의 결과를 합쳐 최종 예측을 합니다.
- 대표 알고리즘:
- XGBoost: 속도와 성능의 밸런스가 좋아 가장 유명합니다.
- LightGBM: 대용량 데이터 처리가 빠르고 메모리를 적게 씁니다.
- CatBoost: 범주형 데이터(Category) 처리에 강점이 있습니다.
- 특징: 정확도(Bias 감소)를 높이는 데 매우 효과적입니다. 하지만 너무 오답에만 집착하면 노이즈까지 학습하는 과적합(Overfitting) 위험이 있습니다.
스태킹 (Stacking): 모델 위의 모델
스태킹은 계층적(Layered) 구조입니다. 여러 모델이 각자 예측한 값을 '새로운 학습 데이터'로 사용하여, 최종 모델(Meta Model)이 다시 학습하는 방식입니다.
- 핵심 개념: "다양한 모델의 예측 결과(Prediction)를 입력 데이터로 삼아 메타 모델이 최종 판단을 내린다."
- 비유: 어려운 환자를 진료하는 상황입니다.
- 내과, 외과, 신경과 전문의(Base Models)가 각자 소견을 냅니다.
- 병원장(Meta Model)은 환자의 차트와 세 전문의의 소견을 모두 종합하여 최종 진단을 내립니다.
- *"내과 선생님은 이럴 때 잘 맞추고, 외과 선생님은 저럴 때 잘 맞추니, 이번엔 외과 선생님 의견을 더 반영하자"*라고 판단하는 것과 같습니다.
- 작동 원리:
- Level 1 (Base Models): 서로 다른 알고리즘(예: KNN, RandomForest, XGBoost)으로 데이터를 학습하고 예측값을 냅니다.
- Dataset 생성: Level 1 모델들이 뱉어낸 예측값들을 모아서 새로운 데이터셋을 만듭니다. (예: A모델 예측값, B모델 예측값... 이 곧 Feature가 됨)
- Level 2 (Meta Model): 이 새로운 데이터셋을 가지고 최종 모델(보통 로지스틱 회귀 등 단순한 모델 사용)을 학습시켜 최종 결과를 냅니다.
- 특징: 단일 모델로는 도달하기 힘든 성능의 한계치를 조금 더 끌어올릴 때 사용합니다. 계산 비용이 비싸고 구조가 복잡합니다.
'AI' 카테고리의 다른 글
MLOps: 머신러닝 파이프라인 자동화 (0) 2026.01.27 인공지능 기초 용어 (0) 2026.01.27 데이터 분석(EDA)부터 머신러닝 전처리까지: Standard Workflow 정리 (0) 2026.01.26 Model과 Gradient Descent (0) 2026.01.25 선택 안됨 데이터 전처리: One-Hot Encoding & Binning (0) 2026.01.23