-
인공지능 기초 용어AI 2026. 1. 27. 16:53
소프트웨어 개발자 관점에서 머신러닝과 딥러닝의 핵심 개념을 정리했습니다. 전통적인 프로그래밍과의 차이점부터, 학습의 종류, 그리고 헷갈리기 쉬운 회귀와 손실함수의 개념까지 다룹니다.
패러다임의 전환: 전통적 방식 vs 머신러닝
가장 큰 차이는 "규칙(Rule)을 누가 만드는가?"입니다.
- 전통적인 프로그래밍 (Explicit Programming)
- 개발자가 직접 로직(함수)을 짭니다.
- 입력: 데이터 + 프로그램(규칙) $\rightarrow$ 출력: 결과값 ($y$)
- 머신러닝 (Machine Learning)
- 데이터를 보고 기계가 스스로 규칙을 찾아냅니다.
- 입력: 데이터 + 정답(결과값 $y$) $\rightarrow$
- 출력: 프로그램(규칙/모델)
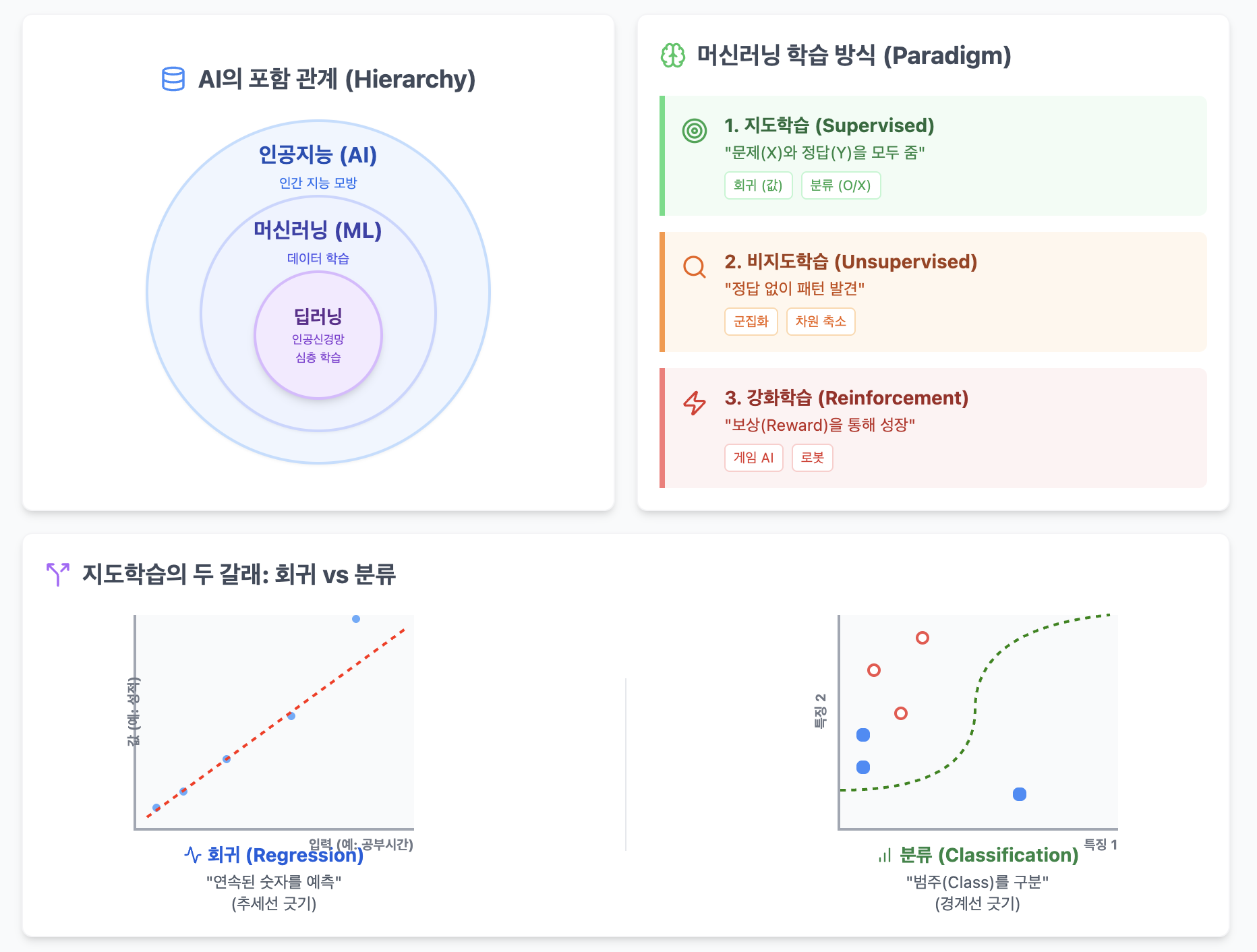
인공지능의 계층 구조 (Hierarchy)
컴퓨터공학적으로 보면 다음과 같은 포함 관계를 가집니다.
- 인공지능 (AI): 인간의 지능을 흉내 내는 모든 기술의 총칭.
- 머신러닝 (ML): 데이터를 통해 기계가 스스로 학습하는 AI의 하위 분야. (지도, 비지도, 강화학습 등이 포함됨)
- 딥러닝 (DL): 머신러닝의 한 방법론. 인간의 뇌 구조를 본뜬 인공신경망(Artificial Neural Network)을 깊게(Deep) 쌓아 만든 기술.
학습 방식의 분류 (Paradigm)
데이터를 어떻게 가르치느냐에 따라 나뉩니다.
학습 종류 핵심 비유 설명 지도학습
(Supervised)"선생님과 문제 풀기" 문제($X$)와 정답($Y$)을 모두 줍니다.
예: 고양이 사진($X$) 주고 "이건 고양이야($Y$)"라고 알려줌.비지도학습
(Unsupervised)"정답 없는 퍼즐 맞추기" 정답($Y$) 없이 데이터($X$)만 던져줍니다. 데이터 자체의 패턴이나 군집을 찾습니다. 준지도학습
(Semi-supervised)"눈치껏 배우기" 소량의 정답 데이터 + 대량의 무정답 데이터. 일부만 배우고 나머지는 유추합니다. 자기지도학습
(Self-supervised)"빈칸 채우기" 데이터의 일부를 가리고, 기계가 스스로 정답을 생성해서 맞추게 합니다. (BERT 등에서 사용) 강화학습
(Reinforcement)"자전거 배우기" 에이전트가 환경 안에서 보상(Reward)과 벌칙(Penalty)을 통해 시행착오를 겪으며 최적의 행동을 학습합니다. 회귀(Regression)와 분류(Classification)
지도학습은 "결과값($y$)의 형태가 무엇이냐?"에 따라 크게 두 가지 문제로 나뉩니다.
회귀 (Regression)
- 목표: **연속적인 숫자(Continuous Value)**를 예측합니다.
- 질문: "얼마입니까?" (How much?)
- 예시:
- 공부 시간에 따른 시험 점수 (85점, 92점...)
- 집 평수에 따른 집값 (5억, 10억...)
- 내일의 기온 (24.5도, 30도...)
- 대표 알고리즘: 선형 회귀 (Linear Regression)
분류 (Classification)
- 목표: 비연속적인 범주(Discrete Category)를 예측합니다. 일명 '클래스(Class)'를 맞히는 문제입니다.
- 질문: "어느 것입니까?" (Which one?)
- 종류:
- 이진 분류 (Binary): 답이 2개 중 하나 (예: 합격/불합격, 스팸/정상)
- 다중 분류 (Multi-class): 답이 여러 개 중 하나 (예: 개/고양이/새, 학점 A/B/C/D)
로지스틱 회귀 (Logistic Regression)
- 이름은 회귀인데, 실제 역할은 '분류'입니다.
- 왜 이런 이름이? 수학적으로는 선형 회귀의 수식을 빌려왔지만, 결과를 시그모이드 함수(S자 곡선)에 통과시켜 0과 1 사이의 확률로 바꿈으로써 이진 분류(Binary Classification) 문제를 풀기 때문입니다.
- 핵심 요약:
- 선형 회귀: 직선을 그어 숫자를 맞힘. (범위: $-\infty \sim +\infty$)
- 로지스틱 회귀: 직선을 구겨서(S자) 확률을 구하고, 이를 통해 O/X를 분류함. (범위: $0 \sim 1$)
딥러닝의 핵심 메커니즘
뉴런과 역치 (Threshold)
- 생물학적 뉴런의 '실무율(All-or-Nothing Law)'을 모방했습니다.
- 입력된 자극의 합이 특정 기준(역치)을 넘지 못하면 신호를 무시하고, 넘으면 다음 뉴런으로 전달합니다.
활성화 함수 (Activation Function)
- 들어온 신호들의 총합을 정해진 규칙에 따라 변환하여 출력하는 함수입니다. (예: Relu, Sigmoid, Softmax 등)
가중치 (Weight, $w$)
- 인공신경망에서 학습이란, 결국 이 가중치($w$)를 수정하는 과정입니다.
- 오차를 줄이기 위해 입력 신호의 세기(중요도)를 조절하는 '다이얼'과 같습니다.
손실 함수: 크로스 엔트로피 (Cross Entropy)
학습이 잘 되고 있는지 채점하는 방법 중 하나로, 주로 분류 문제에서 사용됩니다.
- 의미: "실제 정답 분포($P$)"와 "모델이 예측한 확률 분포($Q$)"가 얼마나 다른지 계산한 값.
- 개발자식 비유 (JSON):
- 정답(Label): [0, 1, 0] (100% 고양이)
- 예측(Prediction): [0.3, 0.6, 0.1] (고양이일 확률 60%)
- 이 두 배열의 차이를 계산한 것이 크로스 엔트로피입니다.
- 결과: 차이가 클수록 Loss가 커지고(학습 필요), 차이가 작을수록 Loss가 작아집니다(정답 근접).
헷갈리기 쉬운 개념: 학습 방식 vs 구현 기술
이 둘은 분류 기준이 다릅니다.
- 학습 방식 (Paradigm): "어떤 데이터로 공부할 것인가?" (지도, 비지도, 강화...)
- 구현 기술 (Method): "어떤 알고리즘/도구로 풀 것인가?" (의사결정나무, SVM, 딥러닝...)
핵심: 딥러닝(도구)은 지도학습에도 쓰이고, 비지도학습에도 쓰이며, 강화학습(알파고 등)에도 쓰입니다.
'AI' 카테고리의 다른 글
Transformer의 원리부터 GPT, LLaMA, Mistral 비교까지 (0) 2026.01.27 MLOps: 머신러닝 파이프라인 자동화 (0) 2026.01.27 Ensemble Learning (1) 2026.01.27 데이터 분석(EDA)부터 머신러닝 전처리까지: Standard Workflow 정리 (0) 2026.01.26 Model과 Gradient Descent (0) 2026.01.25 - 전통적인 프로그래밍 (Explicit Programming)