-
데이터 분석(EDA)부터 머신러닝 전처리까지: Standard Workflow 정리AI 2026. 1. 26. 01:34
데이터 사이언스 프로젝트를 진행할 때, 데이터를 로드하는 순간부터 모델링에 들어가기 직전까지 거쳐야 하는 필수 과정들을 정리했습니다.
이 글에서는 Pandas를 이용한 데이터 핸들링, Seaborn을 이용한 시각화, 그리고 Scikit-learn을 이용한 머신러닝 전처리(Preprocessing)의 표준 패턴을 다룹니다.
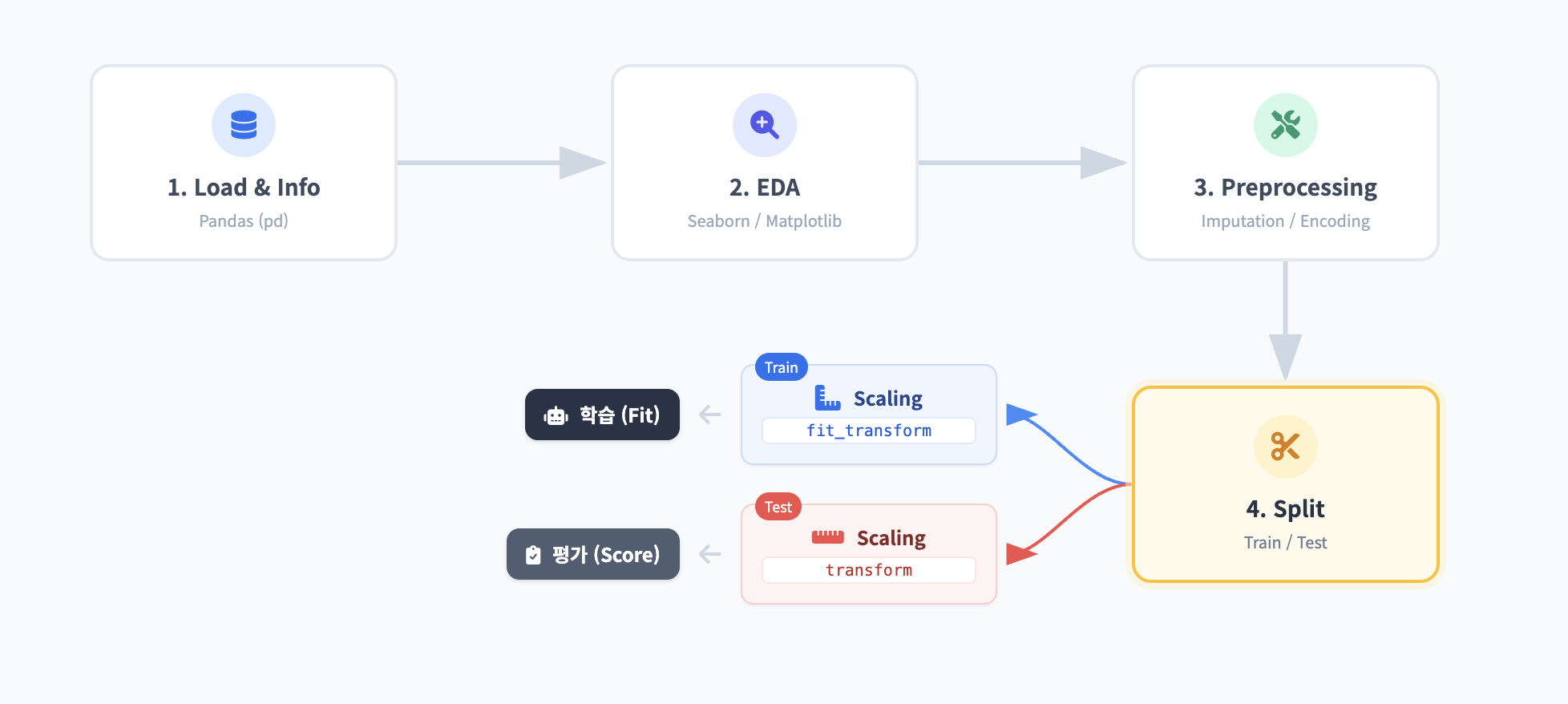
데이터 분석 프로세스는 보통 다음 순서를 따릅니다.
- Load & Info: 데이터를 불러오고 타입과 결측치를 확인한다.
- EDA (Visualization): 시각화를 통해 데이터의 패턴과 이상치를 탐색한다.
- Preprocessing:
- 결측치 처리 (Imputation)
- 인코딩 (Encoding)
- 데이터 분할 (Train/Test Split)
- 스케일링 (Scaling)
도구 준비
본격적인 분석에 앞서, 오늘 사용할 도구들의 역할을 건축과 인테리어에 비유해 정리했습니다.
- NumPy (np) : "단단한 지반 (수치 계산)"
- 모든 연산의 기초가 되는 고성능 배열 라이브러리입니다.
- Pandas (pd) : "만능 관리자 (데이터 핸들링)"
- 엑셀처럼 데이터를 표(DataFrame)로 다루고, 자르고, 요약하는 필수 도구입니다.
- Matplotlib (plt) : "기본 도면 (시각화 기초)"
- 그래프를 그리는 가장 기초적인 도구로, 세밀한 설정이 가능합니다.
- Seaborn (sns) : "인테리어 디자이너 (고급 시각화)"
- Matplotlib을 기반으로, 더 예쁘고 통계적인 그래프를 쉽게 그려줍니다.
- Scikit-learn (sklearn) : "자동화 공장 (머신러닝)"
- 데이터 전처리, 모델 학습, 성능 평가까지 머신러닝의 모든 과정을 담당합니다.
필수 라이브러리 로드
데이터 분석과 머신러닝에 사용되는 표준 라이브러리 구성입니다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno # 머신러닝 전처리 및 분할 from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, LabelEncoder # 실행한 브라우저에서 바로 그림을 볼 수 있게 해줌 %matplotlib inline %config InlineBackend.figure_format = 'retina' # 더 높은 해상도로 출력한다.데이터 로드 및 기초 탐색 (EDA Level 1)
데이터의 구조(Shape)와 타입(Type), 결측치(Null)를 파악하는 단계입니다.
# 데이터 로드 (csv 파일 경로) df = pd.read_csv('your_dataset.csv') pokemon = df.copy() # 1. 데이터 구조 및 샘플 확인 print(f"Dataset Shape: {df.shape}") display(pokemon.head()) # info()로도 보이지만, 정확한 개수를 파악하기 좋습니다. print(pokemon.isnull().sum()) # 2. 기초 통계량 확인 # # 수치형 데이터의 평균, 표준편차, 4분위수 등을 한 번에 보여줍니다. # 수치형 데이터의 스케일(단위) 차이와 이상치(Outlier) 가능성 파악 display(pokemon.describe()) # 3. 데이터 타입 및 결측치 확인 (필수) # info()를 통해 numeric 타입과 object(문자열) 타입을 구분해야 함 pokemon.info() for c in data.columns: print('{} : {}'.format(c, len(data.loc[pd.isnull(data[c]), c].values))) msno.matrix(data)Pands 변환
만약 데이타가 pands기반이 아니면 pandas로 변환해주는것이 좋습니다.
from sklearn.datasets import load_diabetes import pandas as pd # 1. 데이터셋 로드 data = load_diabetes() # 2. Pandas DataFrame으로 변환 (Feature Data) # columns=data.feature_names를 넣어주어야 각 열이 무엇을 의미하는지 알 수 있습니다. df = pd.DataFrame(data.data, columns=data.feature_names) # 3. 타겟(Target) 데이터 추가 # 분석을 위해 Feature와 Target을 하나의 DataFrame에 합쳐두는 것이 편합니다. df['target'] = data.target # 4. 데이터 구조 및 샘플 확인 print(f"Dataset Shape: {df.shape}") display(df.head())데이터 시각화 및 관계 분석 (EDA Level 2)
수치로만 확인하기 어려운 데이터의 분포와 변수 간의 상관관계를 시각화합니다.
1. 타겟(Target) 변수 분포 확인
분류(Classification) 문제일 경우, 정답 데이터(Label)의 비율이 깨져있지 않은지 확인합니다.
# 타겟 변수(예: target_column)의 클래스 불균형 확인 plt.figure(figsize=(8, 5)) sns.countplot(x='target_column', data=df) #sns.scatterplot(data=legendary, y="Type 1", x="Total") plt.title('Distribution of Target Variable') plt.show()2. 변수 간 상관관계 (Correlation Matrix)
수치형 변수들 간의 선형 관계를 파악하여, 다중공선성 문제를 미리 짐작할 수 있습니다.
# 수치형 컬럼만 선택하여 상관계수 계산 numeric_df = df.select_dtypes(include=[np.number]) corr_matrix = numeric_df.corr() plt.figure(figsize=(10, 8)) sns.heatmap(corr_matrix, annot=True, fmt='.2f', cmap='coolwarm') plt.title('Correlation Matrix') plt.show()머신러닝을 위한 데이터 전처리 (Preprocessing)
모델 학습을 위해 데이터를 정제하고 변환하는 과정입니다. Scikit-learn을 활용합니다.
Step 1. 결측치(Missing Values) 처리
# 결측치 확인 print(df.isnull().sum()) # 방법 A: 단순 제거 (데이터가 충분할 때) # df = df.dropna() # 방법 B: 평균/중앙값/최빈값으로 대체 # 예: 'age' 컬럼의 결측치를 평균으로 대체 # df['age'] = df['age'].fillna(df['age'].mean())Step 2. 범주형 데이터 인코딩 (Encoding)
머신러닝 모델은 문자열을 이해하지 못하므로 숫자로 변환합니다.
- Label Encoding: 순서가 있는 범주나 타겟 변수에 적합 (예: Low, Medium, High)
- One-Hot Encoding: 순서가 없는 범주에 적합 (예: Red, Blue, Green)
# Label Encoding 예시 le = LabelEncoder() df['category_column'] = le.fit_transform(df['category_column']) # One-Hot Encoding 예시 (Pandas 활용) df = pd.get_dummies(df, columns=['city'], drop_first=True)Step 3. 변환
데이타가 한쪽으로 너무 치우쳐져 있거나, 불필요한 id, date값들을 처리합니다.
# 앞에서 8글자를 가져오면 연월일(20141013)이 됩니다. df['date'] = df['date'].apply(lambda i: i[:8]).astype(int) del df['id'] del.drop(['id'], axis=1) # 왜도가 높은 수치형 변수 로그 변환 skew_columns = ['sqft_living', 'sqft_lot', 'sqft_above', 'sqft_basement', 'sqft_living15', 'sqft_lot15'] for c in skew_columns: df[c] = np.log1p(df[c])Step 4. 학습/테스트 데이터 분할 (Split)
모델의 일반화 성능을 평가하기 위해 데이터를 나눕니다.
# Feature(X)와 Target(y) 분리 X = df.drop('target_column', axis=1) y = df['target_column'] # Train:Test = 8:2 비율로 분할 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y ) print(f"Train set: {X_train.shape}, Test set: {X_test.shape}")Step 5. 피처 스케일링 (Feature Scaling)
변수 간의 단위(Scale) 차이를 없애 모델 학습 속도와 성능을 높입니다. (Tree 기반 모델 제외, 선형 모델/딥러닝/SVM 등에서 필수)
# 표준화 (Standardization): 평균 0, 분산 1 scaler = StandardScaler() # Train 데이터로 fitting 하고 변환 X_train_scaled = scaler.fit_transform(X_train) # Test 데이터는 Train 데이터의 기준(mean, std)으로 변환만 수행 X_test_scaled = scaler.transform(X_test)초보자가 가장 많이 하는 실수가 있습니다. 바로 테스트 데이터(Test Set)까지 포함해서 스케일링 기준을 잡는 것입니다.
- Train Data (모의고사): fit_transform()을 씁니다. (평균과 분산을 계산하고 변환까지 함)
- Test Data (수능): transform()만 씁니다. (Train 데이터에서 구한 평균과 분산을 그대로 적용)
만약 Test 데이터로 다시 fit을 해버리면, 모의고사를 보는데 수능 정답 분포를 미리 훔쳐보고 공부하는 것과 같습니다. 이를 데이터 누수(Data Leakage)라고 하며, 실무에서 치명적인 실수입니
'AI' 카테고리의 다른 글
인공지능 기초 용어 (0) 2026.01.27 Ensemble Learning (1) 2026.01.27 Model과 Gradient Descent (0) 2026.01.25 선택 안됨 데이터 전처리: One-Hot Encoding & Binning (0) 2026.01.23 데이터 전처리: Missing Data와 Duplicate Data (0) 2026.01.23