-
선택 안됨 데이터 전처리: One-Hot Encoding & BinningAI 2026. 1. 23. 09:18
머신러닝 모델의 성능은 '데이터를 모델이 얼마나 잘 이해할 수 있는 형태로 전달하느냐'에 달려 있습니다. 오늘은 가장 대표적인 전처리 기법인 범주형 데이터 처리(One-Hot Encoding)와 연속형 데이터 처리(Binning)를 심도 있게 다뤄보겠습니다.
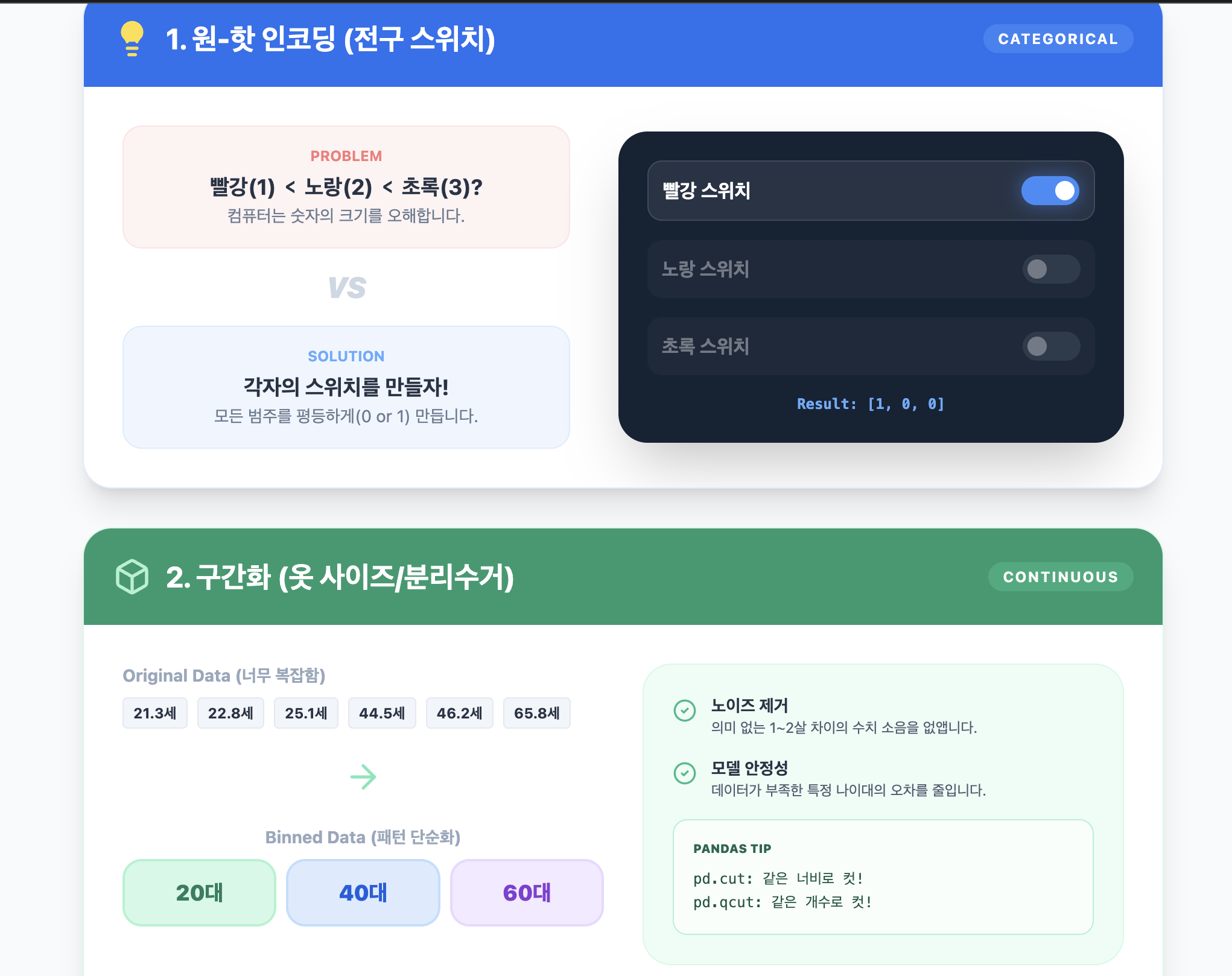
원-핫 인코딩 (One-Hot Encoding)
❓ 개념 및 필요성
머신러닝 알고리즘은 기본적으로 수치 데이터를 계산합니다. 하지만 '서울, 부산' 같은 범주형(Categorical) 데이터는 크기 비교가 불가능합니다. 이를 단순히 1, 2로 바꾸면 모델은 "부산(2)이 서울(1)보다 크다"라는 잘못된 관계를 학습합니다.
원-핫 인코딩은 각 카테고리를 독립된 열로 만들고, 해당하는 데이터에만 1(Hot)을, 나머지는 0(Cold)을 부여하여 데이터 간의 독립성을 보장합니다.
💻 Pandas 실습
import pandas as pd df = pd.DataFrame({'도시': ['서울', '부산', '대구', '서울']}) # drop_first=True는 다중공선성 문제를 방지하기 위해 첫 번째 열을 삭제합니다. one_hot = pd.get_dummies(df, columns=['도시'], drop_first=True) print(one_hot)구간화 (Binning / Discretization)
❓ 개념 및 필요성
연속형 수치 데이터를 특정 범위(Bin)로 나누어 범주형 변수로 변환하는 기법입니다.
- 비선형적 관계 포착: 선형 모델이 파악하기 힘든 '계단식 패턴'을 학습할 수 있게 합니다.
- 노이즈 및 이상치 제어: 미세한 수치 차이나 극단적인 값(Outlier)의 영향력을 줄여 모델의 견고함을 높입니다.
- 해석력 향상: "23세"라는 값보다 "청년층"이라는 그룹이 비즈니스 의사결정에서 더 직관적입니다.
Pandas 실전: pd.cut() vs pd.qcut()
연속형 데이터를 나눌 때 Pandas에서 제공하는 두 함수는 목적이 명확히 다릅니다.
pd.cut() : 절대적 기준 (Equal Width)
데이터의 값(Value)을 기준으로 구간을 나눕니다. 각 구간의 너비가 일정합니다.
- 사용 예: 시험 성적(90점 이상 A, 80점 이상 B...), 연령대(10대, 20대...)
- 주요 파라미터:
- bins: 구간의 개수 또는 경계값 리스트
- labels: 구간별 명칭
- include_lowest=True: 첫 구간의 최솟값 포함 여부
# 점수 데이터를 등급으로 나누기 scores = [95, 62, 85, 40, 78, 92] bins = [0, 60, 70, 80, 90, 100] labels = ['F', 'D', 'C', 'B', 'A'] grade = pd.cut(scores, bins=bins, labels=labels, include_lowest=True) print(grade)pd.qcut() : 상대적 기준 (Equal Frequency)
데이터의 개수(Quantity)를 기준으로 나눕니다. 각 구간에 담긴 데이터 포인트의 수가 일정합니다.
- 사용 예: 소득 상위 10% 등급, 고객 구매 빈도 기반 등급(VIP, Gold...)

핵심 요약 및 선택 가이드
구분 원-핫 인코딩 구간화 (pd.cut) 적용 대상 범주형 데이터 (텍스트 등) 연속형 데이터 (숫자 등) 주요 목적 수치화 및 독립성 확보 노이즈 제거 및 패턴 단순화 수학적 특징 $N$개의 차원 생성 데이터의 스무딩(Smoothing) 주의 사항 차원의 저주 (범주가 너무 많을 때) 정보 손실 (구간을 너무 크게 잡을 때 'AI' 카테고리의 다른 글
데이터 분석(EDA)부터 머신러닝 전처리까지: Standard Workflow 정리 (0) 2026.01.26 Model과 Gradient Descent (0) 2026.01.25 데이터 전처리: Missing Data와 Duplicate Data (0) 2026.01.23 데이터 전처리: Outlier 탐지와 처리: Z-Score부터 IQR까지 (1) 2026.01.23 데이터 전처리: Normalization (0) 2026.01.23