-
Activation FunctionsAI 2026. 1. 29. 12:40
딥러닝 모델을 공부하다 보면 "레이어를 깊게 쌓아야 성능이 좋다"는 말을 자주 듣습니다. 하지만 단순히 선형적인 층만 쌓는다면 아무리 깊게 설계해도 모델은 똑똑해지지 않습니다.
오늘은 모델에 '지능'을 불어넣는 핵심 요소인 활성화 함수의 본질적인 원리와 종류를 파헤쳐 보겠습니다.
활성화 함수란 무엇인가? (개념과 존재 이유)
활성화 함수는 인공신경망의 각 뉴런에서 입력값($wx+b$)을 받아 비선형적으로 변환하여 다음 Layer로 전달하는 함수입니다.
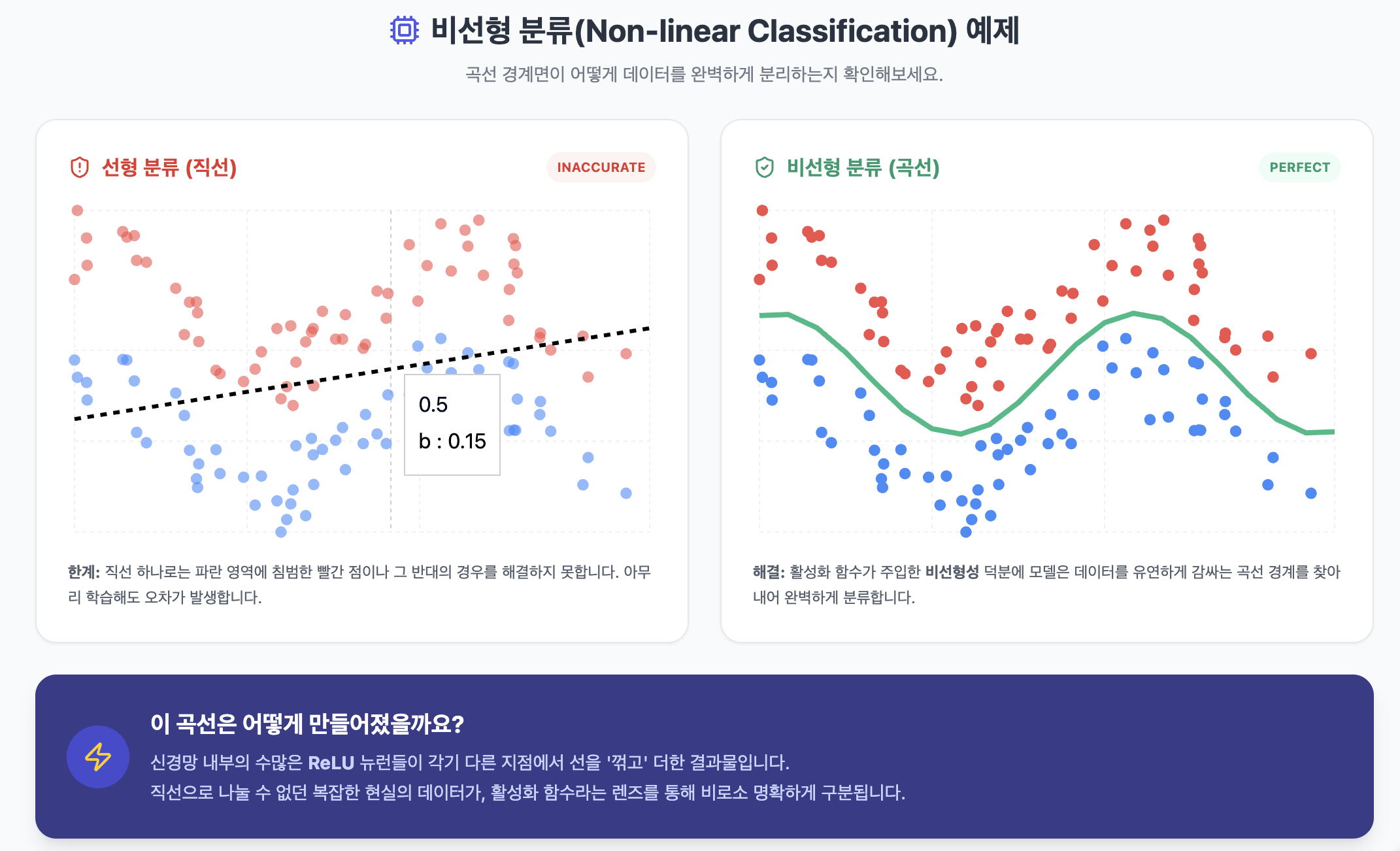
우리 세상의 데이터는 단순한 직선으로 구분되지 않습니다. 강아지와 고양이를 구분하는 경계선은 매우 복잡한 곡선 형태겠죠.
만약 활성화 함수가 없다면, 신경망은 아무리 깊어져도 결국 '거대한 직선' 하나에 불과합니다. 하지만 활성화 함수를 통해 비선형성(Non-linearity)을 주입하면, 레이어를 쌓을수록 모델은 직선을 깎고 다듬어 복잡한 패턴을 학습할 수 있는 능력을 갖추게 됩니다.
즉, 활성화 함수는 "단순한 숫자 계산(선형)을 의미 있는 정보 추출(비선형)로 바꾸는 필터"라고 할 수 있습니다.
왜 하필 비선형(Non-linear)이어야 할까?
가장 중요한 포인트는 "선형 함수만으로는 복잡한 문제를 해결할 수 없다"는 것입니다.
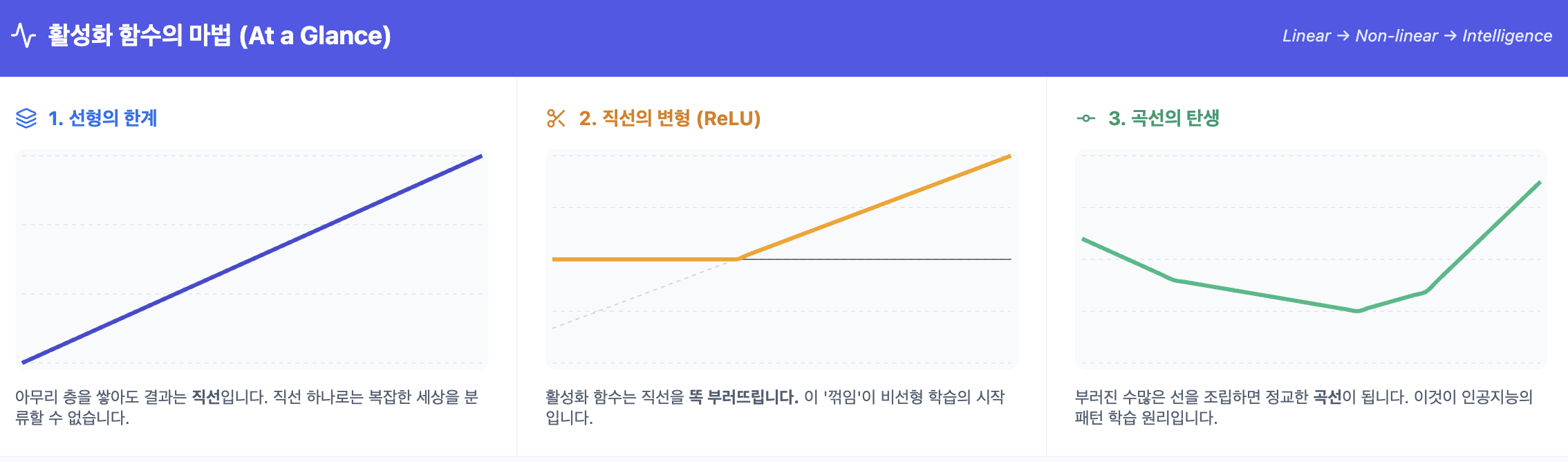
- 선형의 한계: 선형 함수($y=ax$)를 여러 번 중첩해도 결국 하나의 선형 함수($y=Ax$)로 수렴합니다. 즉, 100층을 쌓아도 1층짜리 모델과 수학적으로 차이가 없습니다.
- $y = 2x$ (1층: 2배로 늘려라)
- $y = 3(2x)$ (2층: 그걸 다시 3배로 늘려라)
- $y = 6x$ (결론: 애초에 6배로 늘리는 거랑 뭐가 다른가?)
- 비선형의 마법: 활성화 함수를 통해 비선형성을 주입하면, 직선으로만 그려지던 모델의 경계선이 구부러지고 꺾이며 복잡한 곡선을 그릴 수 있게 됩니다. 이것이 있어야만 신경망이 이미지, 텍스트와 같은 복잡한 패턴을 학습할 수 있습니다.
직선을 '부러뜨리는' 원리
가장 이해하기 쉬운 ReLU 함수($x$가 0보다 작으면 0, 크면 그대로)를 예로 들어보겠습니다.
컴퓨터가 학습하는 기본 식은 $y = ax + b$입니다. 그래프로 그리면 끝없이 뻗어 나가는 직선이죠. 여기에 활성화 함수(ReLU)를 통과시켜 보겠습니다.
- 변환 전: $-\infty$부터 $+\infty$까지 쭉 이어진 직선
- 변환 후 (ReLU 통과): 음수 영역은 모두 0이 되어 바닥에 붙어버리고, 양수 영역만 살아남아 'V'자 형태로 꺾인 선이 됩니다.
여기서 마법이 일어납니다. 직선이었던 것이 활성화 함수를 만나는 순간 '꺾인 선'이 되었습니다. 수학에서 '직선이 아니다'라는 말은 곧 '비선형'이라는 뜻입니다.
꺾인 선들을 조립하여 '곡선' 만들기
"에이, 꺾인 선 하나로는 여전히 복잡한 곡선을 못 그리잖아요?"라고 생각하실 수 있습니다. 하지만 이런 뉴런이 수백, 수천 개가 모이면 이야기가 달라집니다.
- 뉴런 A: 2번 위치에서 꺾이는 선
- 뉴런 B: 5번 위치에서 꺾이는 선
- 뉴런 C: -3번 위치에서 꺾이는 선
이 수많은 꺾인 선들을 레이어에서 더하고 조합하면, 마치 레고 블록을 쌓듯이 아주 세밀하게 굴곡진 곡선을 만들어낼 수 있습니다. (이것을 수학적으로는 '근사'한다고 표현합니다.)
결국 활성화 함수는 매끄러운 직선을 '부러뜨리고 비트는 도구'이며, 이 부러진 조각들을 수만 개 이어 붙여서 복잡한 데이터의 경계선(곡선)을 완성하는 것입니다.
필터링'과 '의사결정'의 원리
활성화 함수는 일종의 합격/불합격 판정관 역할도 합니다.
- 선형 ($wx+b$): 입력된 정보들의 단순한 합계입니다. (예: "이 데이터는 중요도가 75점이야.")
- 활성화 함수: 그 점수를 보고 결정을 내립니다.
- Sigmoid: "75점이니까 0.8 정도의 확률로 합격이야." (부드러운 압축)
- ReLU: "0점 이하는 가차 없이 버리고, 0점 넘는 것만 통과시켜!" (가차 없는 필터링)
이렇게 정보를 그대로 전달하지 않고 변형(압축하거나 무시하거나 꺾거나) 하기 때문에, 층을 거듭할수록 단순한 숫자들의 합이 아닌 '고차원적인 특징'이 추출되는 비선형 체계가 완성되는 것입니다.
"활성화 함수는 무한히 뻗어 나가는 직선을 '꺾고 구부리는' 역할을 합니다."
- 직선의 변형: $wx+b$라는 단순한 직선은 활성화 함수를 만나 꺾인 선(ReLU)이나 휘어진 선(Sigmoid)이 됩니다.
- 곡선의 생성: 이렇게 꺾이고 휘어진 수많은 선이 다음 층에서 서로 더해지고 조합되면서, 비로소 복잡한 세상을 설명할 수 있는 '정교한 곡선'이 만들어집니다.
- 결론: 활성화 함수가 없다면 아무리 층을 쌓아도 직선의 틀을 벗어날 수 없지만, 활성화 함수가 있기에 비로소 모델은 '유연한 사고(비선형 학습)'를 할 수 있게 됩니다.
좋은 활성화 함수의 조건
"비선형성만 추가하면 된다면, 아무 함수나 써도 되지 않을까?"라는 의문이 생길 수 있습니다. 하지만 실제 모델의 성능은 어떤 활성화 함수를 선택하느냐에 따라 천차만별로 달라집니다. 성능이 좋은 활성화 함수는 보통 다음과 같은 핵심 조건을 만족합니다.
기울기 소실(Gradient Vanishing) 방지: "신호의 유통기한"
딥러닝은 역전파(Backpropagation)를 통해 오차를 뒤에서부터 앞으로 전달하며 학습합니다. 이때 활성화 함수의 기울기(Gradient)가 곱해지며 전달됩니다.
- 문제 상황: 시그모이드($\sigma$)의 미분값은 최대치가 0.25입니다. 층을 10개만 거쳐도 $0.25^{10}$이 되어 신호가 거의 0에 수렴합니다. 뒤쪽 층은 공부를 하는데, 앞쪽 층은 "뭐라는 거야?" 하고 신호를 못 받는 상태가 되죠.
- 해결책 (ReLU 등): ReLU는 양수 구간에서 기울기가 1로 일정합니다. 1은 아무리 곱해도 1이죠. 덕분에 100층, 1000층을 쌓아도 초기 입력값 근처의 레이어까지 학습 신호가 싱싱하게 살아있는 채로 전달됩니다.
- 결론: 좋은 활성화 함수는 깊은 층에서도 신호를 죽이지 않고 보존해야 합니다.
Zero-centered (0 중심의 출력): "가중치 업데이트의 안정성"
데이터가 다음 층으로 넘어갈 때, 출력값들이 0을 중심으로 양수와 음수가 골고루 섞여 있어야 합니다.
- 문제 상황 (Sigmoid의 한계): 시그모이드의 출력은 항상 **양수(0~1)**입니다. 이렇게 되면 다음 레이어의 가중치($w$)들을 업데이트할 때, 모든 가중치가 다 같이 커지거나 다 같이 작아지는 현상이 발생합니다.
- 지그재그 현상: 가중치가 최적의 값을 찾아갈 때, 대각선으로 곧장 가지 못하고 **'지그재그'**로 엄청나게 헤매면서 가게 됩니다. 결과적으로 학습 속도가 매우 느려지고 비효율적입니다.
- 해결책 (Tanh, ELU 등): 출력값의 평균이 0에 가까우면 가중치 업데이트가 여러 방향으로 자유롭고 안정적으로 일어납니다.
연산 효율성 (Computational Efficiency): "속도가 곧 성능"
딥러닝 모델은 수백만 번의 활성화 함수 연산을 수행합니다.
- 복잡한 연산: 시그모이드나 Tanh, ELU는 지수 함수($e^x$) 연산이 들어갑니다. 컴퓨터 입장에서는 곱셈이나 덧셈보다 훨씬 무거운 작업입니다.
- 단순한 연산: ReLU는 if (x > 0) return x; else return 0; 끝입니다. 컴퓨터가 가장 잘하는 비교 연산이죠.
- 결론: 똑같은 성능이라면 연산이 가벼운 함수를 써야 더 많은 데이터를, 더 빨리 학습시킬 수 있습니다. 이것이 현대 딥러닝에서 ReLU 계열이 압도적인 지배자가 된 이유입니다.
죽은 뉴런 방지 (Dead Neuron Issues)
좋은 활성화 함수는 '정보의 손실'도 최소화해야 합니다.
- ReLU의 아킬레스건: 음수 영역을 무조건 0으로 만들다 보니, 한 번 음수가 되어 0을 출력하기 시작한 뉴런은 기울기도 0이 되어 다시는 살아나지 못하는 'Dying ReLU' 현상이 생깁니다.
- 개선된 함수 (Leaky ReLU, PReLU): 음수 쪽에도 아주 미세한 통로(0.01 등)를 열어두어, "지금은 비록 음수지만 나중에 다시 살아날 기회"를 줍니다.
📊 활성화 함수(Activation Function) 핵심 요약 비교표
분류 함수명 주요 특징 (원리 및 장점) 단점 및 한계 미분값(기울기) 특징 기초 계단/임곗값 0 또는 1 출력 (초기 모델) 미분 불가로 학습 불가능 0 (학습 신호 소멸) 전통 Sigmoid 출력을 0~1 사이로 압축 기울기 소실(Vanishing) 최대 0.25 (매우 작음) Tanh 중앙값이 0 (Zero-centered) 여전히 기울기 소실 존재 최대 1.0 현대 ReLU 연산 속도 최강, 양수 그대로 음수 영역 뉴런 사멸 (Dying ReLU) 양수에서 무조건 1.0 Leaky ReLU 음수에서 미세한 신호 전달 음수 기울기 설정이 수동적임 음수에서 0.01 등 소량 PReLU 음수 기울기를 학습으로 결정 파라미터 증가로 연산 부담 학습된 알파($\alpha$) 값 ELU 음수에서 부드러운 곡선 수렴 지수($e^x$) 연산으로 속도 저하 음수에서 부드러운 전이 최신 SELU 자체 정규화(Self-normalizing) 특정 조건에서만 동작함 고정된 상수가 곱해짐 GELU BERT, GPT 등 최신 모델 표준 ReLU보다 계산량 많음 확률 기반의 부드러운 곡선 💡 '활성화 함수 선택 가이드'
표 바로 아래에 아래 내용을 덧붙여주면 포스팅의 실용성이 더 높아집니다.
- 가장 무난한 선택: 일단 ReLU를 먼저 쓰세요. 가장 빠르고 성능이 검증되었습니다.
- 기울기 소실이나 뉴런 사멸이 걱정될 때: Leaky ReLU나 ELU로 교체해 보세요.
- 최신 NLP(자연어 처리) 트렌드를 따를 때: Transformer 기반 모델을 공부하신다면 GELU를 눈여겨보세요.
- 출력층(Output Layer)의 고정석:
- 이진 분류: Sigmoid
- 다중 분류: Softmax
- 회귀 분석(수치 예측): 활성화 함수 없음(Linear) 또는 ReLU
'AI' 카테고리의 다른 글
Optimizer (0) 2026.01.29 Loss Function (0) 2026.01.29 딥러닝의 심장: 체인룰(Chain Rule)과 역전파(Backpropagation) 완벽 정리 (0) 2026.01.29 Perceptron (0) 2026.01.29 언어모델은 어떻게 똑똑해질까? : Pre-training, SFT, 그리고 RLHF (0) 2026.01.28 - 선형의 한계: 선형 함수($y=ax$)를 여러 번 중첩해도 결국 하나의 선형 함수($y=Ax$)로 수렴합니다. 즉, 100층을 쌓아도 1층짜리 모델과 수학적으로 차이가 없습니다.