-
언어모델은 어떻게 똑똑해질까? : Pre-training, SFT, 그리고 RLHFAI 2026. 1. 28. 01:28
ChatGPT와 같은 거대언어모델(LLM)이 사람처럼 자연스럽게 대화하고, 전문적인 지식을 뽐낼 수 있는 비결은 무엇일까요? 언어모델이 지식을 배우고 다듬어지는 3단계 학습 과정(Pre-training → Fine-tuning → RLHF)을 정리해 보았습니다.
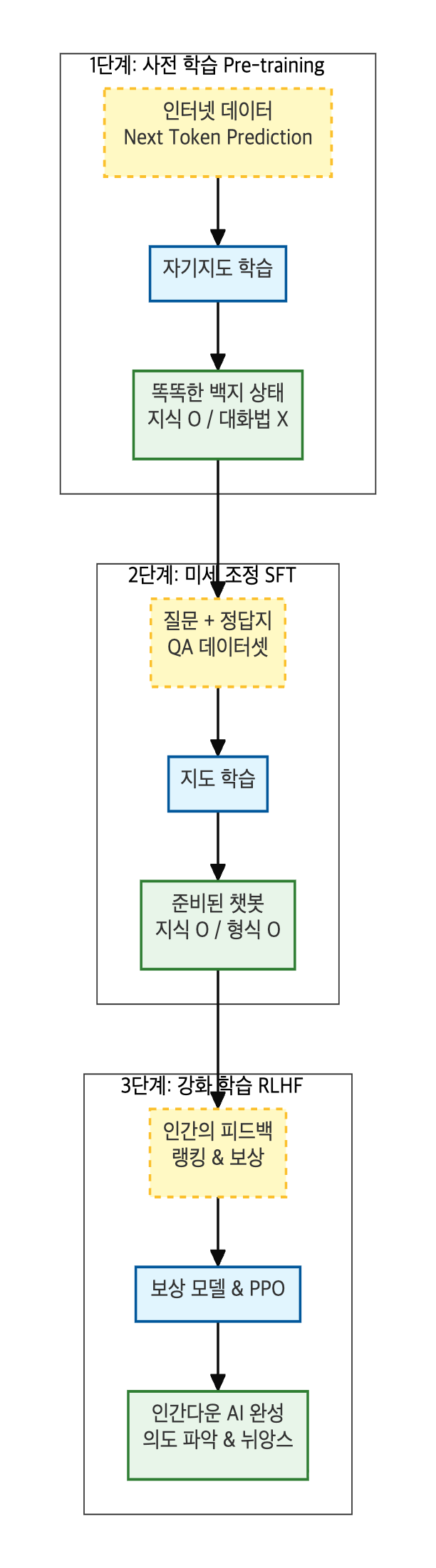
1단계: 똑똑한 백지 상태 만들기, 자기지도학습 (Pre-training)
언어모델이 세상의 지식을 배우는 가장 첫 번째 단계입니다.
- 핵심 키워드: Pre-training(사전 학습), Next Token Prediction(다음 단어 예측)
- 어떻게 학습하나? (자기지도학습): 사람이 일일이 정답을 알려주지 않습니다. 인터넷상의 방대한 텍스트 자체가 문제이자 정답이 됩니다.
예시: "대한민국의 수도는 [ ? ]" $\rightarrow$ 텍스트 원문에서 "서울"임을 확인하고 학습. - 학습 효과: 데이터의 과거(문맥)를 보고 미래(다음 단어)를 맞추는 과정에서 문법, 문맥, 상식, 논리 등을 스스로 깨우칩니다.
- 상태:엄청난 양의 독서를 통해 지식은 풍부하지만, 아직 사용자가 원하는 답변 형식이 무엇인지는 모르는 '똑똑한 백지' 상태입니다.
2단계: 대화 예절 배우기, 지도학습 (SFT)
사전 학습을 마친 모델을 우리가 원하는 용도(챗봇 등)에 맞게 다듬는 과정입니다.
- 핵심 키워드: Fine-tuning, SFT (Supervised Fine-Tuning)
- 어떻게 학습하나? (모범 답안 따라 하기): 사람이 직접 만든 질문(Prompt)과 이상적인 답변(Label) 쌍을 정답지로 제공합니다.
입력: "사과를 영어로 뭐야?" 정답(Label): "사과는 영어로 Apple입니다." - 학습 효과: 모델은 "아, 질문을 받으면 이렇게 공손하게 대답해야 하는구나"라는 지시 따르기(Instruction Following) 능력을 배웁니다.
- 상태: 이제 대화의 형식을 갖춘 '기본적인 챗봇'이 됩니다. 하지만 여기서 멈추면 한계가 있습니다.
3단계: 인간다움의 완성, 강화학습 (RLHF)
ChatGPT가 그토록 자연스러운 이유는 바로 이 RLHF(Reinforcement Learning from Human Feedback) 단계 때문입니다. 복잡한 수식 없이 개념만 이해하면 충분합니다.
1. 기존 방식(SFT)의 문제점은 무엇인가요?
단순히 사람의 답안을 따라 하게 만드는 지도학습(SFT)만으로는 다음과 같은 한계에 부딪힙니다.
- 비용 문제: 모든 세상의 질문에 대해 사람이 일일이 "이게 완벽한 정답이야"라고 작문해서 가르치기에는 시간과 돈이 너무 많이 듭니다.
- 답변의 질(Quality): 모델이 사람이 써준 답안만큼은 하지만, 그 이상 창의적이거나 훌륭한 답을 내놓기는 어렵습니다.
- 지시 불이행: 학습하지 않은 뉘앙스나 복잡한 질문에는 엉뚱한 대답을 하거나 문맥을 놓치는 경우가 발생합니다(마치 말은 할 줄 알지만 눈치 없는 야생마 같은 상태).
2. 해결책: 적은 수의 레이블을 어떻게 활용했나?
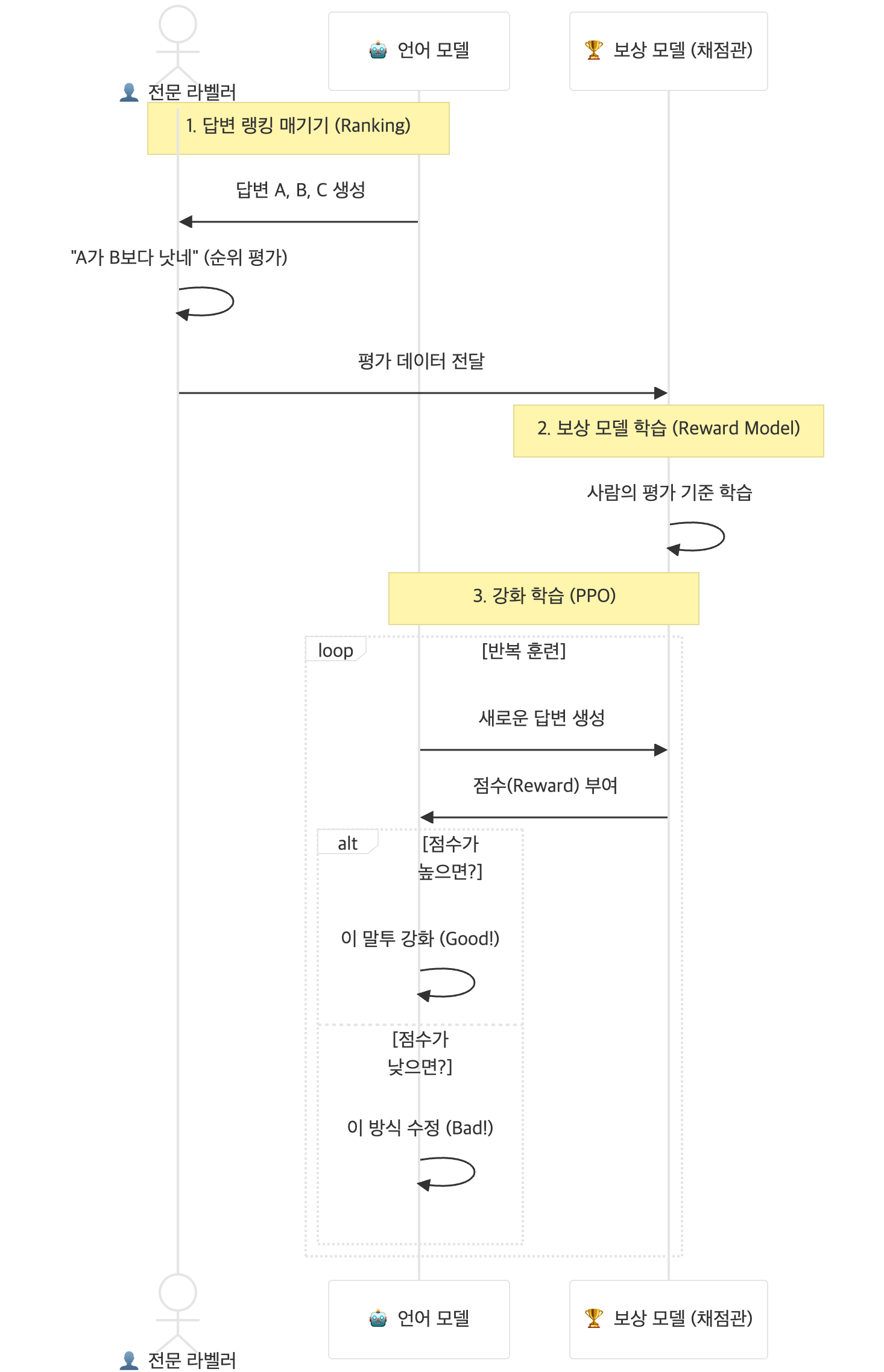
RLHF는 "정답을 직접 써주는 것(Writing)보다, 무엇이 더 잘 쓴 글인지 고르는 것(Ranking)이 훨씬 쉽다"는 점에 착안했습니다.
- 전문 라벨러의 역할 변화:
- 사람이 모든 답변을 작성하는 대신, AI가 생성한 2~3개의 답변을 보고 "A가 B보다 낫네"라고 순위만 매깁니다.
- 보상 모델(Reward Model) 구축:
- 사람이 매긴 순위 데이터를 학습하여, 나중에는 사람이 없어도 AI가 쓴 글을 보고 "이건 80점, 저건 30점"이라고 점수를 매겨주는 채점관 AI를 만듭니다.
3. 핵심: 보상(Reward)을 어떻게 활용했나?
이제 모델은 정해진 답을 외우는 게 아니라, 점수(보상)를 잘 받는 법을 스스로 깨우칩니다.
- 강화학습 과정: AI가 답변을 내놓을 때마다 '채점관 AI'가 점수를 줍니다.
- "공손하게 말하니 점수가 높네? $\rightarrow$ 앞으로 더 공손하게 해야지."
"욕설을 섞으니 점수가 깎이네? $\rightarrow$ 절대 하지 말아야지."
- "공손하게 말하니 점수가 높네? $\rightarrow$ 앞으로 더 공손하게 해야지."
- 결과:모델은 이 보상(점수)을 최대화하는 방향으로 자신의 파라미터를 미세하게 조정합니다. 이를 통해 인간이 선호하는 말투, 뉘앙스, 가치관을 대규모로 학습하게 됩니다.
요약: 언어모델 학습 3단계 비유
단계 학습 방법 비유 핵심 활동 1단계 Pre-training
(자기지도학습)도서관의 독학생 책을 읽으며 지식과 언어를 습득 (말하는 법은 모름) 2단계 SFT
(지도학습)과외 선생님과 공부 족보(QA)를 보며 대화 예절과 형식을 배움 3단계 RLHF
(강화학습)실전 훈련과 칭찬 사람들이 좋아하는 답을 할 때마다 '칭찬 스티커(보상)'를 받아, 스스로 더 좋은 답을 찾음 결국 적은 수의 고품질 데이터로 기본기(SFT)를 잡고, 보상 시스템(RLHF)을 통해 인간의 의도에 맞게 모델을 정교하게 튜닝한 것이 현재 AI의 성공 방정식입니다.
'AI' 카테고리의 다른 글
딥러닝의 심장: 체인룰(Chain Rule)과 역전파(Backpropagation) 완벽 정리 (0) 2026.01.29 Perceptron (0) 2026.01.29 Transformer의 원리부터 GPT, LLaMA, Mistral 비교까지 (0) 2026.01.27 MLOps: 머신러닝 파이프라인 자동화 (0) 2026.01.27 인공지능 기초 용어 (0) 2026.01.27