-
딥러닝의 Overfitting 해결사: Dropout 이해하기AI 2026. 1. 21. 07:56
딥러닝 모델이 복잡해질수록 모델은 훈련 데이터에 너무 완벽하게 적응해버리는 과적합(Overfitting) 문제에 직면하게 됩니다. 이를 해결하기 위해 2014년 힌튼(Geoffrey Hinton) 교수팀이 제안한 혁신적인 기법이 바로 드롭아웃(Dropout)입니다.
드롭아웃이란 무엇인가?
드롭아웃은 신경망 학습 과정에서 레이어의 뉴런을 임의의 확률로 비활성화(0으로 만듦)하는 기법입니다.
- Fully Connected Layer의 문제: 모든 뉴런이 연결되어 있으면 특정 뉴런들끼리 너무 강하게 결합(Co-adaptation)되어, 특정 특징에만 의존하는 현상이 발생합니다.
- 드롭아웃의 해결책: 매 학습 단계(Iteration)마다 무작위로 뉴런을 '끄기' 때문에, 모델은 특정 뉴런에 의존하지 않고 더 보편적인 특징을 학습하게 됩니다.
에포크(Epoch)와 배치(Batch)의 정의
언제 뉴런을 무작위로 설정하느냐"입니다. 정답은 "매 배치(Batch) 데이터가 모델을 통과할 때마다"입니다. 그리고 이것은 에포크(Epoch)가 반복될 때 더욱 강력한 효과를 발휘합니다.
- 1에포크(Epoch): 내가 가진 전체 학습 데이터셋을 모델이 한 번 다 본 상태입니다.
- 2에포크: 똑같은 전체 데이터를 다시 처음부터 한 번 더 보는 상태입니다.
- 배치(Batch): 전체 데이터를 한꺼번에 공부하기 힘드니, 작게 쪼갠 문제 묶음입니다.
드롭아웃의 실제 타임라인 (구체적 예시)
레이어 1에 뉴런 A, B가 있고, 레이어 2에 뉴런 C, D가 있는 신경망을 가정해 봅시다. 배치 사이즈를 100으로 설정했을 때, 드롭아웃은 다음과 같이 매번 다른 마스크를 씌웁니다.
- 첫 번째 배치 (데이터 1~100번 학습 시):
- 레이어 1: A(OFF), B(ON)
- 레이어 2: C(ON), D(OFF)
- 결과: 이번 공부에서는 B에서 C로 가는 정보만 전달되며 학습됩니다.
- 두 번째 배치 (데이터 101~200번 학습 시):
- 레이어 1: A(ON), B(OFF) (A가 다시 살아남!)
- 레이어 2: C(OFF), D(ON)
- 결과: 이전과는 완전히 다른 경로인 A에서 D로 가는 정보 위주로 학습됩니다.
- 세 번째 배치 (데이터 201~300번 학습 시):
- 레이어 1: A(ON), B(ON)
- 레이어 2: C(OFF), D(OFF)
- 결과: 이번에는 첫 번째 레이어는 다 쓰지만, 두 번째 레이어는 모두 쉬게 됩니다.
...이 과정을 에포크가 끝날 때까지 무한히 반복합니다.
왜 드롭아웃이 효과적일까? (핵심 원리)
드롭아웃이 성능을 높이는 이유는 크게 두 가지 관점으로 설명할 수 있습니다.
앙상블(Ensemble) 효과
드롭아웃을 적용하면 학습할 때마다 매번 다른 구조의 네트워크를 훈련시키는 것과 같은 효과를 냅니다. 수많은 서로 다른 얇은 모델(Thinned Network)을 학습시킨 뒤, 테스트 시에 이들을 결합하여 사용하는 앙상블 기법이 모델 내부에 자연스럽게 녹아드는 것입니다.
동조화(Co-adaptation) 방지
특정 뉴런의 가중치가 너무 커지면 다른 뉴런들은 그 뉴런의 결과에 묻어가는 경향이 생깁니다. 하지만 드롭아웃을 통해 언제든 그 뉴런이 사라질 수 있다는 환경을 만들면, 각 뉴런은 스스로 유의미한 특징을 추출할 수 있도록 강건(Robust)하게 학습됩니다.
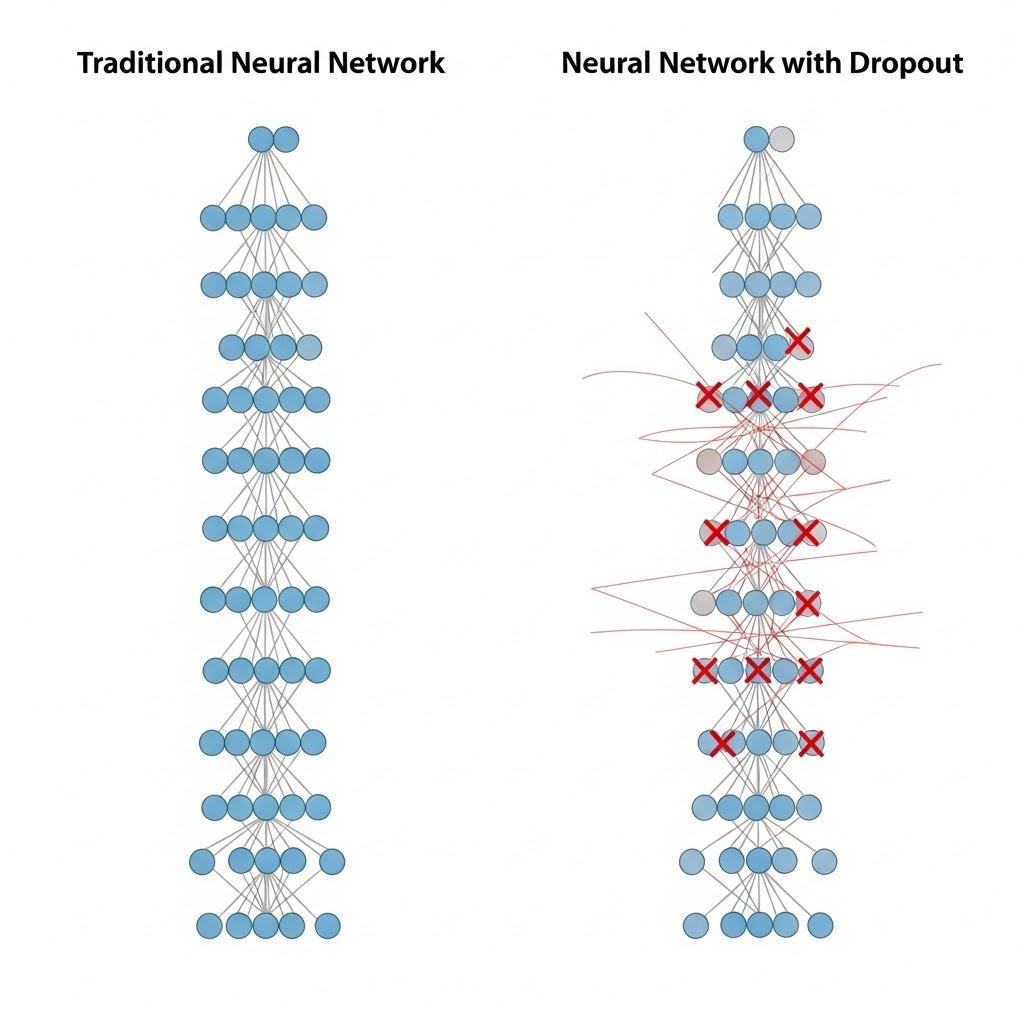
드롭아웃 사용 시 주의사항
드롭아웃은 매우 강력하지만, 올바르게 사용하기 위해 몇 가지를 기억해야 합니다.
- 학습 시와 테스트 시의 차이:
- 학습(Training): 설정한 확률 $p$에 따라 뉴런을 무작위로 끕니다.
- 추론(Inference/Testing): 모든 뉴런을 다 사용합니다. 다만, 학습 때 뉴런을 껐던 만큼 출력이 커져 있으므로, 전체 가중치에 확률 $p$를 곱하여 스케일을 조정합니다. (최근 프레임워크들은 'Inverted Dropout'을 통해 학습 시에 미리 스케일링을 처리하여 테스트 시 별도 조작이 필요 없게 구현되어 있습니다.)
- 드롭아웃 비율(Dropout Rate): 보통 $0.2 \sim 0.5$ 사이의 값을 사용합니다. 너무 높으면 학습이 제대로 안 되는 과소적합(Underfitting)이 발생하고, 너무 낮으면 적용하지 않은 것과 다를 바 없게 됩니다.
- 왜 에포크 단위가 아니라 배치 단위일까?
만약 에포크 단위로 뉴런을 끈다면, 그 에포크 동안 모델은 고정된 절반짜리 네트워크로만 모든 데이터를 보게 됩니다. 그러면 모델은 다시 그 '절반짜리 네트워크'에 과적합(Overfitting)되어 버립니다.
하지만 배치마다 뉴런을 계속 바꿔주면:- 모델은 매 순간 "내 옆의 뉴런이 누가 살아남을지 모르는" 아주 불안정한 환경에 놓입니다.
- 뉴런 A는 "B가 꺼질 때를 대비해서 나 혼자서도 정보를 잘 전달해야지!"라고 학습하게 됩니다.
- 이 과정에서 모델은 특정 뉴런에 의존하는 법을 잊어버리고, 더 보편적이고 강력한 특징(Feature)을 찾아내려고 노력하게 됩니다.
'AI' 카테고리의 다른 글
L1, L2 Regularization (0) 2026.01.21 Batch Normalization (1) 2026.01.21 Overfitting과 Regularization (0) 2026.01.21 분류 모델의 성능 성적표, ROC 곡선과 AUC (0) 2026.01.20 Precision-Recall Curve 와 Average Precision(AP) (0) 2026.01.20