-
RNN의 Inductive Bias 파헤치기AI 2026. 4. 5. 14:58
컴퓨터 비전에 CNN이 있다면, 시계열(Time-series)과 자연어(NLP)에는 RNN이 있습니다. CNN이 "이미지는 공간적으로 가까운 것끼리 관련이 있어!"라는 고정관념을 가졌다면, RNN은 어떤 '현명한 고정관념(Inductive Bias)'을 가지고 있을까요?
오늘은 순차 데이터를 요리하기 위해 RNN이 설계된 핵심 메커니즘인 Sequentiality와 Time Invariance, 그리고 맥락을 담는 Hidden State의 비밀을 알아보겠습니다.

RNN의 Inductive Bias: "세상의 모든 데이터는 흐름이 있다"
RNN(순환 신경망)은 데이터의 '순서'가 정보의 본질이라는 강력한 사전 가정(Assumptions)을 바탕으로 설계되었습니다.
- 왜 필요한가? 문장에서 "사과가 나를 먹는다"와 "내가 사과를 먹는다"는 구성 성분은 같지만 의미는 천지차이입니다. RNN은 이 '선후 관계'라는 지름길을 모델 구조에 미리 깔아준 것입니다.
- 핵심: RNN은 Sequentiality(순차성)와 Time Invariance(시간 불변성)라는 두 가지 강력한 Bias를 주입받았습니다.
Sequentiality (순차성): "과거는 미래의 복선이다"
"현재의 상태는 바로 직전의 상태에 의존한다"는 개념이 바로 Sequentiality입니다.
- 인과 관계 (Causality): 데이터 $t$ 시점의 의미는 $t-1$ 시점에서 온 정보가 있을 때만 온전히 완성됩니다.
- RNN의 전략 (Recurrence): RNN은 출력값을 다시 입력으로 사용하는 재귀적 루프를 가집니다. 이는 "과거의 기억(Hidden State)을 현재의 판단에 반영하라"는 규칙을 모델 구조에 직접 주입한 것입니다.
Time Invariance (시간 불변성): "언제 나타나도 법칙은 같다"
CNN에 Translation Invariance가 있다면, RNN에는 Time Invariance가 있습니다.
- 핵심 기술: Weight Sharing (가중치 공유): RNN은 첫 번째 단어를 처리할 때나, 백 번째 단어를 처리할 때나 똑같은 가중치($W$)를 사용합니다.
- 이유: "사랑해"라는 단어가 문장 맨 앞에 나오든 맨 뒤에 나오든, 그 단어가 가진 근본적인 의미를 해석하는 '필터'는 같아야 하기 때문입니다.
- 효과: 덕분에 모델은 입력 데이터의 길이에 상관없이 동일한 규칙을 적용해 특징을 추출할 수 있으며, 학습해야 할 파라미터 수를 획기적으로 줄여줍니다.
요약: CNN vs RNN의 Inductive Bias 한눈에 보기
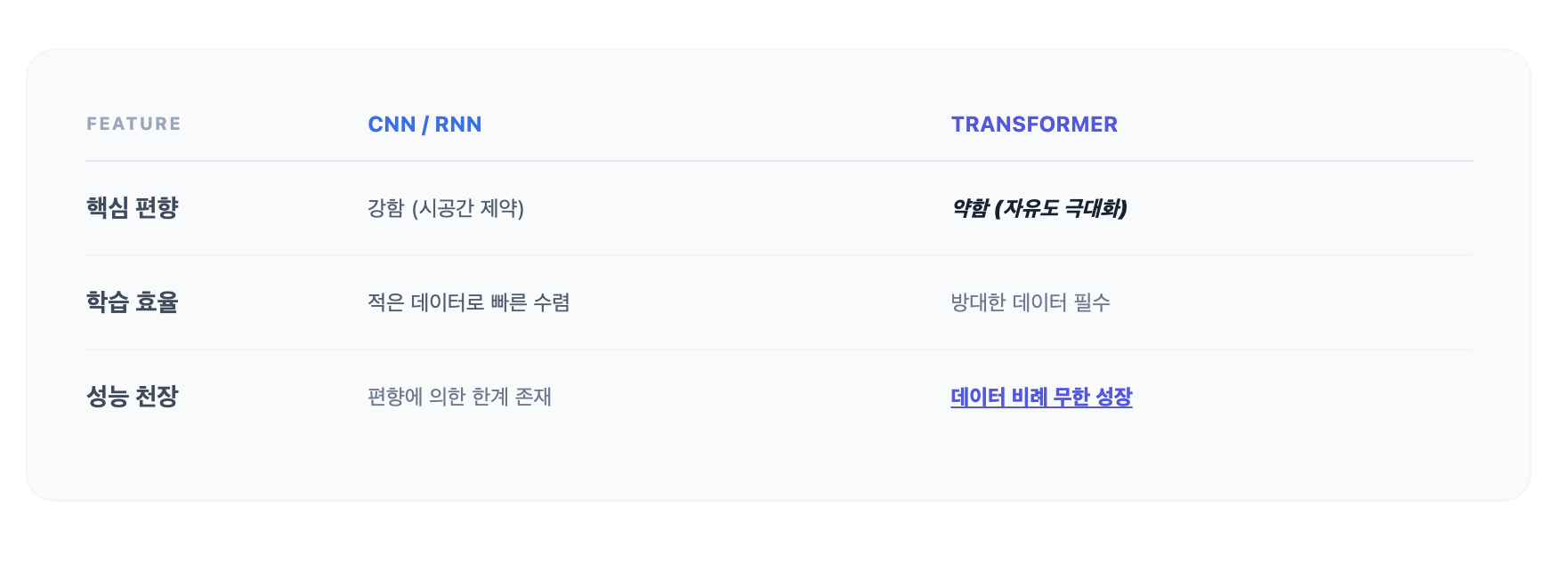
구분 CNN (이미지) RNN (시계열/언어) 핵심 Bias Locality (공간적 국부성) Sequentiality (시간적 순차성) 불변성 Translation Invariance (위치 불변) Time Invariance (시간 불변) 연산 도구 필터(Kernel) 공유 가중치(Weight) 공유 데이터 특징 픽셀 간의 관계 시점(Step) 간의 관계 번외: Transformer는 왜 RNN과 CNN을 압도했는가?
최근 인공지능의 대세인 Transformer(Attention)는 역설적으로 "Inductive Bias(귀납적 편향)를 최소화"했기 때문에 성공했습니다.
- 인위적인 제약의 제거: RNN은 "가까운 과거가 중요하다"는 편향이 있고, CNN은 "인접 픽셀이 중요하다"는 편향이 있습니다. 하지만 Transformer는 Attention(주의집중) 메커니즘을 통해 데이터의 모든 부분을 동시에 쳐다봅니다.
- 자유로운 관계 학습: "첫 단어와 마지막 단어가 가장 중요할 수도 있어!"라는 가능성을 열어둔 것이죠. 모델에 미리 "이래야 해"라고 가이드를 주는 대신, 데이터 스스로가 관계를 찾도록 내버려 둔 것입니다.
데이터의 힘: "초반엔 약하지만, 한계점(Threshold)을 돌파하면?"
Inductive Bias가 적다는 것은 모델에게 '지름길'을 알려주지 않는 것과 같습니다.
- 초기 학습의 어려움: 가이드라인이 없으니, 데이터가 적을 때는 RNN이나 CNN보다 훨씬 멍청해 보입니다. 아무런 사전 정보 없이 무한한 가능성 속에서 헤매기 때문입니다. (실제로 ViT나 Transformer 계열은 소량 데이터에서 성능이 매우 낮습니다.)
- 데이터 폭식과 임계점 돌파: 하지만 데이터가 '무지막지하게' 많아지면 이야기가 달라집니다. 인간이 준 좁은 고정관념(Bias)에 갇히지 않고, 방대한 데이터 속에서 인간이 미처 생각지 못한 복잡한 패턴을 스스로 학습해 버립니다.
- 결론: 어느 순간 임계점을 넘어서는 순간, 인간이 설계한 꼼수(Bias)를 쓴 모델들의 성능 천장을 뚫고 올라가 버리는 '한계점 돌파'가 일어나는 것이죠. 이것이 바로 우리가 지금 목격하고 있는 거대 언어 모델(LLM)의 시대입니다.
"결국 효율의 CNN/RNN이냐, 무한한 가능성의 Transformer냐의 싸움입니다."
인간의 직관(Bias)을 넣어 효율적으로 배울 것인가, 아니면 편향을 버리고 데이터의 힘으로 본질에 다가갈 것인가. 이 철학적 차이가 현대 AI의 흐름을 갈랐다고 해도 과언이 아닙니다.
선호(Sun-ho)님의 티스토리 독자들에게 "Inductive Bias는 학습의 지름길이지만, 때로는 거대한 성장을 가로막는 벽이 되기도 한다"는 메시지를 던져주면 아주 멋진 마무리가 될 것 같습니다!
'AI' 카테고리의 다른 글
NLP 성능 평가: 단순 수치를 넘어 '맥락'을 읽는 법 (0) 2026.04.18 딥러닝의 본질: 고차원 노이즈에서 저차원의 '알맹이'를 찾는 여정 (0) 2026.04.05 프롬프트의 시대를 넘어 '컨텍스트 엔지니어링 (1) 2026.03.20 LLM 시대의 표준 프레임워크: RAG(검색 증강 생성), LangChain (0) 2026.03.17 모델 최적화 기법들 (1) 2026.03.15