-
T5(Text-to-Text Transfer Transformer)AI 2026. 3. 11. 11:18
5는 Text-to-Text Transfer Transformer의 약자입니다. 보시다시피 'T'가 무려 5개나 들어가죠. 구글의 작명 센스가 엿보이는 대목입니다. 😆
단순히 이름만 재미있는 게 아닙니다. T5는 기존의 BERT나 GPT와는 또 다른 'Text-to-Text'라는 혁신적인 패러다임을 제시했습니다.
T5는 Transformer를 기반으로 만들어진 아키텍처로 text-to-text 방법을 사용합니다. BERT와 차이점을 몇 개 볼 수 있습니다.
우선 causal decoder를 bidirectional architecture에 추가하였고, pre-training tasks를 fill-in-the-blank cloze task로 대체했다는 것입니다.
Shared Text-To-Text Framework
T5의 가장 큰 특징은 모든 NLP 문제를 "텍스트를 넣고 텍스트를 출력하는" 형식으로 통일했다는 점입니다.
- 기본 구조: 입력(Text) -> 모델 -> 출력(Text)
- 장점: 번역, 요약, 분류, 문법 검사 등 서로 다른 성격의 문제들을 하나의 모델, 하나의 손실 함수(Loss Function), 동일한 하이퍼파라미터로 학습시킬 수 있습니다.

"모델이 문제를 어떻게 구분하나요?"
모든 형식을 통일하면 모델이 지금 번역을 해야 하는지, 요약을 해야 하는지 헷갈릴 수 있겠죠? 이를 위해 T5는 입력값 앞에 Task-specific Prefix(작업별 접두사)를 붙여줍니다.
예시:
- 번역: translate English to German: That is good. → Das ist gut.
- 감성 분석: sst2 sentence: The movie is great. → positive
- 요약: summarize: [긴 문장들...] → [요약된 문장]
T5의 엔진: C4 데이터셋 (Colossal Clean Crawled Corpus)
T5 논문의 핵심은 "데이터의 양과 질이 모델 성능에 어떤 영향을 주는가?"를 탐구하는 것이었습니다. 이를 위해 구글이 직접 만든 재료가 바로 C4입니다.
C4와 T5는 무슨 관계인가요?
한마디로 "T5는 C4라는 거대 도서관에서 사전학습(Pre-training)된 천재 모델"입니다. 구글은 T5라는 설계도(Architecture)를 만들고, C4라는 엄청난 데이터를 쏟아부어 "기초 언어 능력"을 마스터하게 했습니다.
왜 그냥 데이터가 아니라 'Clean'인가요?
C4의 원재료는 웹 전체를 긁어모은 'Common Crawl'입니다. 하지만 인터넷에는 쓰레기 정보가 너무 많죠. 그래서 구글은 엄청난 세척(Cleaning) 과정을 거쳤습니다.
필터링 항목 상세 내용 품질 필터링 너무 짧은 문장이나 마침표 없는 문장, 'Lorem Ipsum' 같은 더미 텍스트 제거 중복 제거 인터넷에 널려 있는 동일한 광고 문구나 기사를 하나만 남기고 삭제 코드 제거 자바스크립트 등 프로그래밍 언어({ } 포함 문구) 제거 금기어 필터링 혐오 표현, 음란물 등이 포함된 페이지를 리스트 기반으로 철저히 차단 결과: 위키피디아보다 수십 배 거대한 750GB의 깨끗한 영어 텍스트 데이터가 탄생했고, 이를 통해 학습한 T5는 오버피팅 없이 비약적인 성능 향상을 이뤄냈습니다.
학습 방식의 진화: Span Corruption (Modified MLM)
BERT는 단어 하나하나를 마스킹(Masking)했지만, T5는 'Span Corruption'이라는 방식을 사용합니다.
T5은 입력에 corrupted token을 넣어 더 좋은 성능을 낼 수 있도록 하였습니다. 이를 denoising objectives라고 합니다.
T5는 타겟을 랜덤으로 샘플링하고, 입력 시퀀스의 15%의 token을 single sentinel token()로 대체하였습니다.
각 sentinel token은 어떤 wordpiece에도 대응되지 않는 특별한 토큰으로, 시퀀스에 유일한 토큰 ID로 지정되어 voca에 추가됩니다. 또한 연속된 단어는 하나의 sentinel token로 여겨집니다.
타켓 토큰은 입력에서 사용된 sentinel token과 final sentinel token()입니다. 이를 시각화하면 아래와 같습니다.
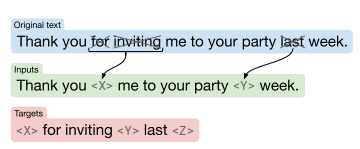
여기서 Target은 모델에게 "전체 문장을 다 다시 쓸 필요 없어. 너는 <X> 자리에 뭐가 들어갈지, <Y> 자리에 뭐가 들어갈지 순서대로 정답만 말해줘!"라고 지시하는 것과 같습니다.
- 성격: 사전 학습(Pre-training) 타스크
- 목적: 언어의 구조, 문법, 그리고 세상의 일반적인 지식을 머릿속에 집어넣는 것.
- 특징: 정답이 따로 있는 데이터를 사람이 만들어줄 필요가 없습니다. 그냥 인터넷 글(C4)에서 아무 단어나 가리고 맞히게 하면 되니까요. (Self-supervised learning)
왜 이렇게 '정답지'를 만드나요? (Denoising)
원래 문장을 훼손(Corrupt) 시킨 다음, 노이즈를 제거해서 원래대로 **복원(Denoising)**하는 능력을 기르기 위해서입니다.
- BERT 방식: "빈칸에 들어갈 단어는 '사과'야." (단답형)
- T5 방식 (Text-to-Text): "<X> 자리에는 '맛있는 사과를'이 들어가야 해." (서술형)
이렇게 서술형으로 정답을 쓰게 훈련시키면, 모델이 문맥을 파악하는 능력뿐만 아니라 새로운 문장을 생성하는 능력까지 동시에 엄청나게 좋아집니다.
아키텍처의 비밀: Causal with Prefix Masking
T5는 Encoder-Decoder 구조를 사용하지만, 어텐션 마스킹 방식이 독특합니다.
- Prefix의 중요성: "translate English to German" 같은 명령어(Prefix)가 가려지면 모델은 뭘 해야 할지 모르게 됩니다.
- 해결책: 명령어 부분은 모두가 서로를 볼 수 있게(Fully-visible) 하고, 결과물을 생성하는 부분만 뒤를 보지 못하게(Causal) 막는 Causal with Prefix 마스킹을 적용했습니다.
1. Fully-visible (BERT 방식)
- 특징: 말씀하신 대로 패딩만 가리고 나머지는 다 봅니다.
- 용도: 문장의 전체적인 의미를 파악할 때 최고입니다.
- T5에서의 위치: T5의 인코더(Encoder)가 이 방식을 씁니다.
2. Causal (GPT 방식)
- 특징: 패딩뿐만 아니라 '미래의 단어'도 가립니다. (i번째 단어는 i+1번째 단어를 못 봄)
- 용도: 다음 단어를 하나씩 생성(Generation)해야 할 때 필수입니다. 미리 정답을 보면 학습이 안 되니까요.
3. Causal with Prefix (T5가 고민한 하이브리드)
T5는 "모든 문제를 텍스트 생성으로 풀겠다"고 했죠? 그러다 보니 "명령어(Prefix)는 인코더처럼 다 보고, 정답은 디코더처럼 하나씩 생성하게 할 순 없을까?"라는 고민이 생긴 겁니다.
- Prefix 부분 (translate English to German): 여기는 BERT처럼 패딩만 가리고 서로 다 보게 합니다. (작업 지시를 완벽히 이해해야 하니까요.)
- 정답 부분 (Das ist...): 여기는 GPT처럼 미래 단어를 가립니다. (한 단어씩 생성해야 하니까요.)
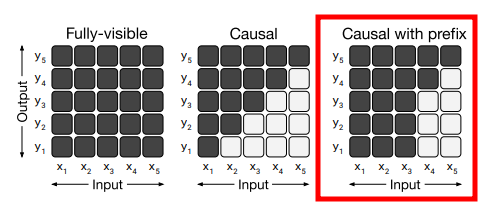
다른 모델과 T5의 또다른 차이점은 Transformer 아키텍처입니다.
아래의 그림에서 block은 시퀀스이고, 선은 attention입니다. 진한 선은 fully-visible masking이고, 연한 선은 causal masking을 나타내죠. T5는 오른쪽과 같이 언어모델에 prefix를 추가해 입력에 fully-visible masking할 수 있도록 하였습니다. 즉 encoder에는 양방향 attention을, decoder(generation)에서는 단방향 attention을 사용하는 거죠.
즉, "T5는 왼쪽의 'Encoder-Decoder' 구조를 선택했지만, 그 내부에서 Prefix를 처리하는 논리(Prefix는 다 보여주고 답은 가린다)는 오른쪽 'Prefix LM'의 철학과 일맥상통한다"

① 왼쪽: Encoder-Decoder (T5의 실제 선택)
- 구조: 인코더와 디코더가 나뉘어 있습니다.
- 특징: 인코더($x$ 부분)는 진한 선(양방향)으로 정보를 꽉 채워 이해하고, 디코더($y$ 부분)는 연한 선(단방향)으로 단어를 하나씩 생성합니다.
- 결론: T5 연구팀은 실험 결과, 이 구조가 가장 성능이 좋다고 결론지었습니다.
② 중간: Language Model (GPT 방식)
- 구조: 처음부터 끝까지 연한 선(단방향)뿐입니다.
- 특징: 입력($x$)을 읽을 때도 미래를 못 보게 막혀 있어서, 전체 문맥을 이해하는 능력이 상대적으로 떨어집니다.
③ 오른쪽: Prefix LM
- 구조: 디코더 하나만 쓰지만, 앞부분(Prefix)만큼은 진한 선(양방향)을 적용합니다.
- 설명: "translate English to German" 같은 Prefix($x_1, x_2, x_3$) 구간은 서로를 다 볼 수 있게(Fully-visible) 열어주고, 그 뒤에 답을 쓰는 구간부터만 가리는 방식입니다. 이것이 바로 Causal with Prefix Masking의 핵심 원리입니다.
Fine Tunning: Closed-Book Question Answering (폐쇄형 질의응답)
이 타스크는 T5의 '지식 암기력'을 테스트하는 가장 놀라운 작업입니다.
- 무슨 뜻인가요? 보통 인공지능이 질문에 답할 때는 관련 문서를 옆에 펴놓고 답을 찾습니다(오픈북). 하지만 Closed-Book은 외부 문서(위키피디아 등)를 전혀 보지 않고, 오직 사전 학습(C4) 때 머릿속(파라미터)에 저장된 지식만으로 답을 내놓는 것입니다.
- 의의: 이 과정을 통해 T5가 단순한 '문장 생성기'를 넘어, 세상의 지식을 내재화한 '지식 베이스(Knowledge Base)' 역할을 할 수 있음을 증명했습니다.
- 결과: T5 연구팀과의 퀴즈 대결에서도 승리할 정도로 뛰어난 상식 수준을 보여주었죠!

'AI' 카테고리의 다른 글
Transformer의 진화: 아키텍처 변형부터 최신 LLM 레시피까지 (0) 2026.03.15 Switch Transformer (0) 2026.03.11 BERT: 진짜 양방향(Bi-directional) 언어 모델의 탄생 (0) 2026.03.10 GPT(Generative Pre-Training Transformer) (0) 2026.03.10 NLP 데이터 증강 (1) 2026.03.06