-
TransformerAI 2026. 2. 24. 10:28
Attention 메커니즘의 등장으로 RNN 기반 Seq2Seq 모델은 크게 개선되었습니다. RNN과 Attention이 결합된 형태는 2014년도부터 2017년도까지 Seq2Seq의 구현체로 광범위하게 사용되었습니다. 이 조합은 특히 기계 번역, 음성 인식, 텍스트 요약 등 다양한 분야에서 뛰어난 성능을 보였습니다.
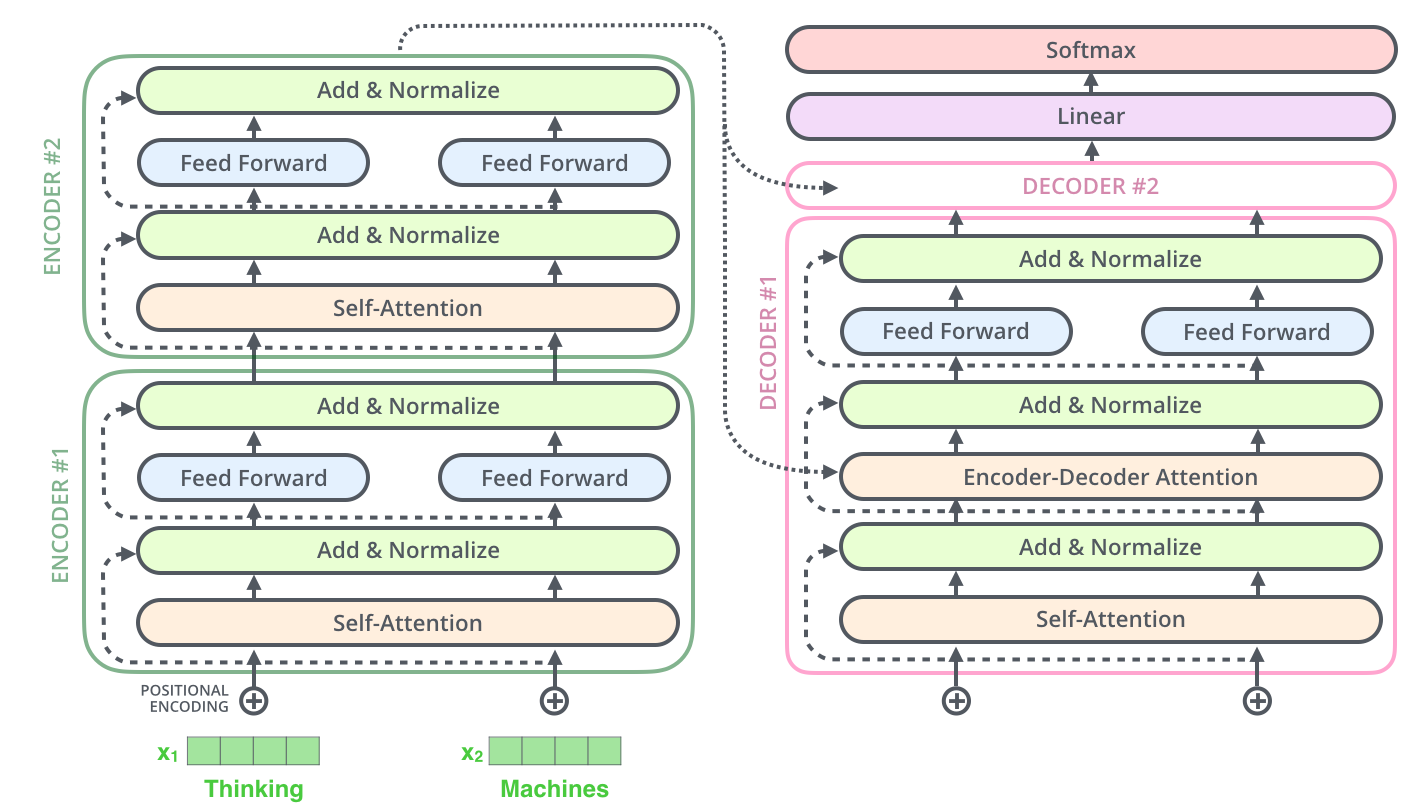
Transformer: Attention만으로 구현된 새로운 시대
Seq2Seq 구현의 패러다임을 완전히 바꾼 것은 바로 Transformer 아키텍처의(Self-Attention 기반 Encoder-Decoder 구조)등장입니다. Transformer는 오로지 Attention 메커니즘만을 사용하여 Seq2Seq 문제를 해결하는 새로운 방식을 제시했습니다. 이 모델은 복잡한 RNN 구조를 제거하고, 전체 시퀀스를 한 번에 처리할 수 있는 구조로 설계되었습니다. 이로 인해 학습 속도가 크게 향상되었으며, 더 긴 시퀀스와 더 깊은 네트워크에 대한 처리가 가능해졌습니다. 특히 특정한 도메인이나 문제에 국한되는 네트워크 형태가 아니기 때문에 자연어 처리 문제 이외에도 다양한 문제에 범용적으로 적용 가능한 구조를 가지고 있습니다.
연속성이라는 개념을 과감히 배제 하였습니다. 대신 Attention으로 각 단어들의 상관관계를 구하는 데 집중 하였죠. 문장을 모델링 한다는 것은 주어진 단어를 보고 모르는 단어에 확률을 할당하는 것입니다. 연속성이 배제된 채로 문장을 모델링 한다는 것은, 단순히 생각하면 입력으로 빨간 사과 노란 바나나가 들어가는 것과 노란 사과 빨간 바나나가 들어가는 것이 동일하게 취급되는 셈입니다.
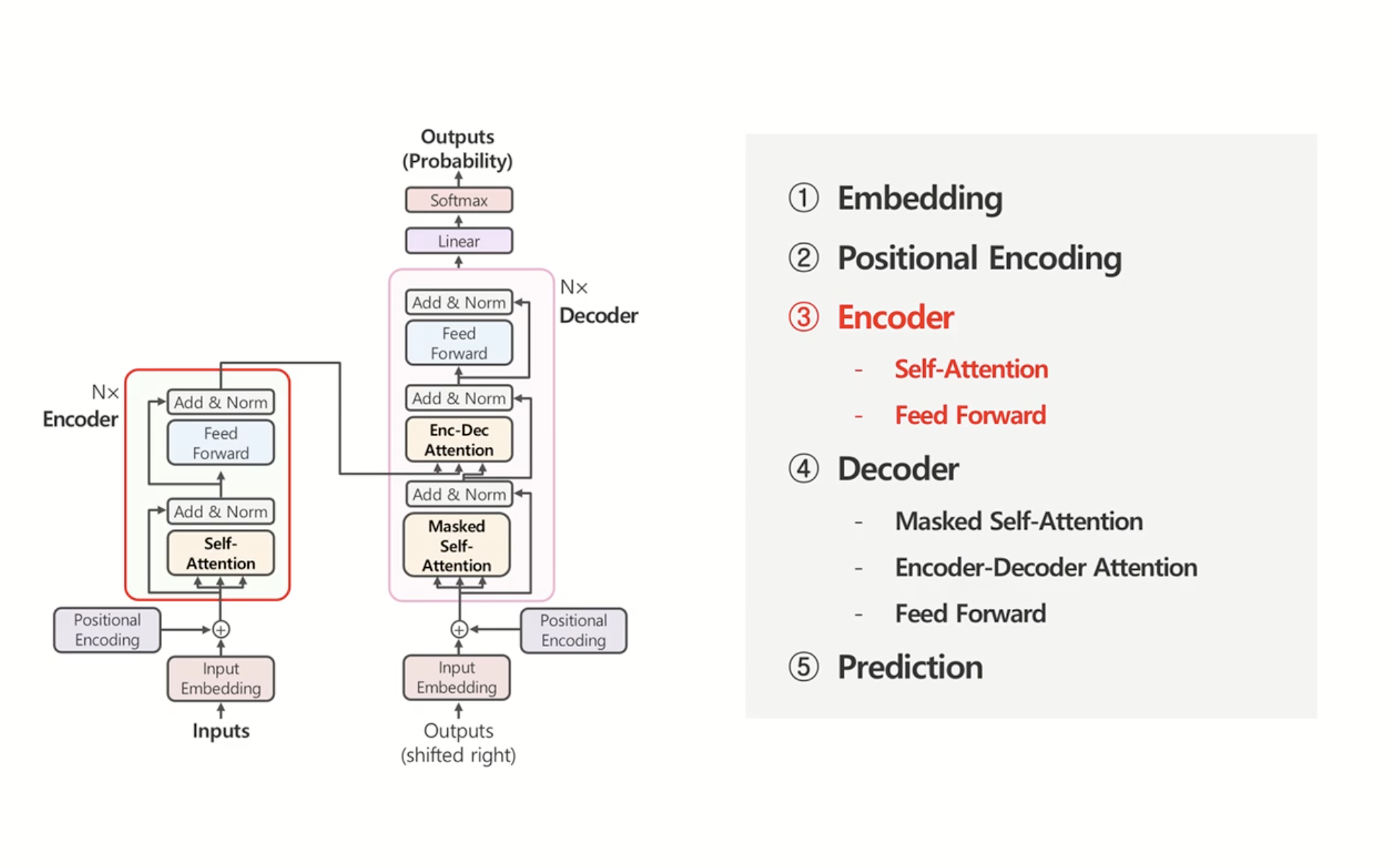
모델 구조 관련 하이퍼파라미터
가장 핵심적인 뼈대를 구성하는 설정값들입니다.
하이퍼파라미터 기호 설명 표준값 (Base) Embedding Dimension $d_{model}$ 단어 임베딩 및 각 층의 출력 차원 수 512 Number of Layers $N$ 인코더와 디코더가 각각 쌓이는 층의 개수 6 Number of Heads $h$ Multi-head Attention에서 병렬로 나누는 헤드 수 8 Feed-Forward Dimension $d_{ff}$ 내부 Feed-Forward 신경망의 은닉층 차원 수 2048 - 참고: $d_{model}$은 반드시 $h$로 나누어떨어져야 합니다. (각 헤드의 차원 $d_k = d_{model} / h$) 64
여러개의 Layer가 있는이유
1. 정보의 추상화 (Hierarchical Learning)
데이터가 층을 통과할수록 모델이 파악하는 정보의 깊이가 달라집니다.
- 하위 층: 단어 사이의 문법적 관계나 인접한 단어와의 단순한 연관성을 파악합니다.
- 중간 층: 문장 전체의 흐름이나 대명사가 가리키는 대상 등을 분석하기 시작합니다.
- 상위 층: 문장의 주제, 의도, 비유적 의미 등 고도의 추상적인 정보를 완성합니다.
2. 표현력(Capacity)의 확장
층이 많아질수록 모델이 학습할 수 있는 파라미터(Weight)의 수가 늘어납니다. 이는 모델이 더 방대하고 복잡한 규칙을 가진 데이터를 처리할 수 있는 '그릇'이 커지는 것을 의미합니다.
3. 반복적인 정교화 (Refinement)
하나의 Self-Attention 층이 문장을 완벽히 이해하는 것은 어렵습니다.
- 첫 번째 층에서 대략적인 관계를 파악하고,
- 그 결과물을 다음 층의 Attention이 다시 한번 정밀하게 검토하는 과정을 반복하면서 정보의 정확도를 높입니다.

입력
구분 Input Embedding (Encoder) Output Embedding (Decoder) 대상 번역할 대상 (원문) 이미 생성된/생성할 단어 (정답) 데이터 예시 I, am, a, student <SOS>, 나는, 학생 특이사항 여러문장 문장 전체를 한 번에 입력 Shifted Right를 통해 미래 단어를 가림 목적 질문의 맥락을 파악하기 위해 다음 단어를 예측하기 위한 참고 자료로 사용 Output Embedding (디코더의 입력)
훈련시
디코더에 들어가는 '이미 번역된(또는 번역할) 정답 문장'을 숫자로 바꾸는 단계입니다. 훈련 시에는 정답(Ground Truth)을 이미 알고 있기 때문에, 디코더에 정답 문장을 한꺼번에 집어넣습니다.
여기서 핵심은 Shifted Right(오른쪽으로 한 칸 밀기)입니다.
- 상황: 정답인 "나는 학생 이다"를 모델에게 학습시킴. 정답 문장이 [<sos>, 나는, 학생, 이다]라면, 이 전체 시퀀스를 한 번에 입력
- Shifted Right의 실제 모습:
- 진짜 정답: ["나는", "학생", "이다"]
- 디코더 입력: ["<SOS>", "나는", "학생"] (문장 시작 토큰을 앞에 붙이고 마지막 단어는 제외)
- 왜 이렇게 하나요?
- 모델이 "나는"을 예측할 때, 정답지에서 "나는"을 미리 보고 베끼지 못하게 하기 위해서입니다.
- 대신 <SOS>(시작) 토큰을 보고 첫 단어인 "나는"을 맞추게 연습시키는 것이죠
- Masking (커닝 방지): 정답지를 통째로 넣었지만, 현재 위치보다 뒤에 있는 단어(미래의 정답)는 보지 못하도록 Masked Multi-Head Attention으로 가려버립니다.
Teacher Forcing
학습의 효율을 위해 '학생(모델)'이 오답을 말해도 '선생님(정답 데이터)'이 바로 다음 정답을 알려주며 학습을 진행하는 방식입니다.
- 교사 강요가 없을 때 (일반적인 방식)
모델이 첫 단어부터 틀리면 뒤의 학습이 줄줄이 망가집니다.- 1단계: 모델이 "I" 대신 "You"라고 오답을 냅니다.
- 2단계: 모델은 자기가 말한 "You"를 바탕으로 다음 단어를 예측합니다. → "are"라고 예측합니다.
- 결과: 첫 단어 하나 틀렸을 뿐인데 문장 전체가 엉뚱한 방향으로 흘러가며 학습 시간이 굉장히 오래 걸립니다.
- 교사 강요가 있을 때 (Teacher Forcing)
모델이 틀려도 바로 잡아주어 학습의 '맥락'을 유지합니다.- 1단계: 모델이 "I" 대신 "You"라고 오답을 냅니다.
- 2단계: 선생님(훈련 데이터)이 개입합니다. "너는 'You'라고 했지만, 진짜 정답은 'I'야. 자, 다음 단어 예측해봐." 하며 "I"를 강제로 입력해줍니다.
- 3단계: 모델은 다시 올바른 정답인 "am"을 예측할 수 있는 기회를 얻습니다.
훈련시 한꺼번에 정답이 들어가는 것 자체가 티쳐 Forcing입니다.
추론시
실제로 번역을 수행할 때는 정답지가 없습니다. 이때는 모델이 방금 전단계에서 스스로 뱉은 단어가 다음 단계의 입력(정답지 역할)이 됩니다.추론시에는 RNN처럼 순차적...
- 자기 회귀(Auto-regressive): 자신이 만든 출력을 다시 자신의 입력으로 사용합니다.
- 과정:
- <SOS> 입력 $\to$ "나는" 출력
- <SOS> 나는 입력 $\to$ "학생" 출력
- <SOS> 나는 학생 입력 $\to$ "이다" 출력
Postitional Encodding(PE)
트랜스포머는 RNN과 다르게 입력 시퀀스는 병령구조로 처리 합니다.그리고, 핵심인 셀프 어텐션(Self-Attention) 메커니즘은 '치환 불변성(Permutation Invariance)'이라는 특징을 가집니다. 이는 입력되는 단어들의 순서가 바뀌어도 어텐션 맵의 행렬 값들이 위치만 바뀔 뿐, 결과적으로 출력되는 벡터들의 집합은 동일하다는 뜻입니다. 즉, PE가 없다면 모델은 "나는 학생 이다"와 "이다 학생 나는"을 단순한 단어의 뭉치(Bag-of-words)로만 인식하여 문맥적 차이를 파악하지 못하게 됩니다.
- 짝수 차원: $PE(pos, 2i) = \sin(pos / 10000^{2i/d_{model}})$
- 홀수 차원: $PE(pos, 2i+1) = \cos(pos / 10000^{2i/d_{model}})$
- $pos$: 단어의 위치 (첫 번째 단어면 0, 두 번째면 1...)
- $i$: 벡터의 차원 인덱스
- $d_{model}$: 임베딩 벡터의 전체 차원
이렇게 계산된 위치 정보 벡터를 단어의 의미가 담긴 임베딩 벡터에 요소별 더하기(Element-wise Addition)를 하여 최종 입력값으로 사용함으로써 모델에게 위치 정보를 주입합니다.
"나는 학생 이다"라는 문장에서 각 단어가 아래와 같이 4차원 벡터로 변환되었다고 가정합니다. (가상의 숫자입니다.)
단어 (pos) x1 x2 x3 x4 나는 (0) 0.1 0.2 0.3 0.4 학생 (1) 0.5 0.6 0.7 0.8 공식에 따라 $pos=1$ (학생)일 때의 위치 값을 계산해 봅시다. $d_{model}=4$이므로 $i$는 0, 1, 2, 3이 됩니다.
- $i=0$ (짝수, $\sin$): $\sin(1 / 10000^{0/4}) = \sin(1) \approx \mathbf{0.841}$
- $i=1$ (홀수, $\cos$): $\cos(1 / 10000^{0/4}) = \cos(1) \approx \mathbf{0.540}$
- $i=2$ (짝수, $\sin$): $\sin(1 / 10000^{2/4}) = \sin(1/100) \approx \mathbf{0.010}$
- $i=3$ (홀수, $\cos$): $\cos(1 / 10000^{2/4}) = \cos(1/100) \approx \mathbf{0.999}$
결과: '학생'의 위치 벡터 $PE(1) = [0.841, 0.540, 0.010, 0.999]$
이제 원래의 단어 임베딩에 방금 구한 위치 정보를 더합니다.
$$\text{최종 벡터} = \text{단어 임베딩} + \text{위치 인코딩}$$구분 i=0 i=1 i=2 i=3 단어 '학생' ($pos=1$) 0.5 0.6 0.7 0.8 위치 정보 ($PE$) + 0.841 + 0.540 + 0.010 + 0.999 결과 (Input to Transformer) 1.341 1.140 0.710 1.799 어떻게 최종에서 위치를 판별하나요? (학습의 힘)
모델이 처음부터 "0.841은 1번 위치다"라고 정해놓고 들어가는 게 아닙니다. 학습(Backpropagation) 과정을 통해 모델의 가중치($W$)들이 다음과 같이 최적화됩니다.
- Self-Attention 연산: 단어 간의 유사도를 계산할 때, 위치 값이 더해진 상태로 내적(Dot Product)이 일어납니다.
- 위치 벡터들은 서로 다른 주기($\sin, \cos$)를 갖기 때문에, 상대적인 거리에 따라 내적 값이 규칙적으로 변합니다.
- 모델은 수많은 문장을 보면서 "아, 이 위치 벡터 패턴이 더해진 단어들은 서로 가까이 있구나/멀리 있구나"라는 기하학적 관계를 스스로 학습하여 파악하게 됩니다.
소실되지 않는 이유 (Residual Connection)
'소실' 문제를 해결하기 위해 Transformer에는 잔차 연결(Residual Connection)이라는 장치가 있습니다.
- 각 층을 지날 때마다 원래 입력값(위치 정보가 포함된 값)을 계속 뒤로 전달해서 더해줍니다.
- 덕분에 위치 정보라는 '이정표'가 층이 깊어져도 사라지지 않고 마지막 출력층까지 전달될 수 있습니다.
임베딩의 정보를 해치지 않으면서 위치를 효율적으로 표현하기 위해 다음 네 가지 전제가 반영되었습니다:
- 각 Time-step마다 고유의 Encoding 값을 출력해야 한다.
- 서로 다른 Time-step이라도 같은 거리라면 차이가 일정해야 한다.
- 순서를 나타내는 값이 특정 범위 내에서 일반화가 가능해야 한다.
- 같은 위치라면 언제든 같은 값을 출력해야 한다.
Positional Encoding의 두 가지 방법과 그 한계
- 각 단어에 0~1 사이의 값을 더한다. 0을 첫 번째 단어로, 1을 마지막 단어로 한다.
- -> 문장의 길이에 따라 더해지는 값이 가변적이다. 따라서 단어 간의 거리(Delta)가 일정하지 않다.
- 각 단어에 선형적으로 증가하는 정수를 더한다.
- -> 단어 간의 거리(Delta)가 일정해지는 것은 좋지만 범위가 무제한이기 때문에 값이 매우 커질 수 있고 모델이 일반화하기 어려워진다.
💡 Transformer 데이터 처리 흐름도
1. Raw Text → Tokenizer : 허깅페이스
- 문장을 쪼개서 번호를 매깁니다.
2. Padding (0 발생): 허깅페이스
- 문장 길이를 맞추려고 뒤에 0을 채웁니다.
- (예: [15, 42, 0, 0])
3. Embedding & PE Addition (데이터 오염)
- 위치 정보(PE)를 더하는 순간, 0이었던 자리에 복잡한 숫자가 생깁니다!
- (예: [0.1, 0.4, 0.8, -0.2] ← 패딩인데 진짜 단어처럼 보임)
4. 데이터의 분기 (Split)
- [길 1: 잔차 연결] → 오염된 숫자 그대로 들고 나중에 더해주려고 대기합니다.
- [길 2: 어텐션 연산]
5. Padding Mask (무력화 베이스 깔기)
- "아까 0이었던 자리는 숫자가 생겼어도 가짜야!"라고 적힌 가림막 지도를 만듭니다.
- 이 지도에는 패딩 위치에 $-\infty$(음수 무한대)라는 거대한 장벽이 쳐져 있습니다.
6.어텐션 연산
단계 과정 (Layer/Operation) 입력 차원 출력 차원 주요 특징 및 역할 1 Input Embedding - 512 단어(정수 Index)를 512차원 수치형 벡터로 변환 2 Positional Encoding 512 512 단어에 순서 정보($\sin, \cos$)를 더함 (※ 패딩 자리 오염 발생) 3 Padding Mask 생성 (신호) (지도) [베이스 깔기] PE로 오염된 패딩 자리에 $-\infty$ 장벽(지도)을 설정 4 Multi-Head Attention 512 512 [정화] 3번의 지도를 참조해 패딩 확률을 **0%**로 무시하며 관계 파악 5 Add & Norm (1차) 512 512 잔차 연결(Add) 및 데이터 정규화(Norm) 6 Feed-Forward (FFN) 512 512 2048차원으로 확장 후 다시 512로 축소 (정보 가공) 7 Add & Norm (2차) 512 512 층의 최종 출력 정돈 (4~7단계를 $N=6$번 반복) 8 Linear Layer 512 30,000 임베딩 벡터를 단어장(Vocab) 크기만큼 펼침 9 Softmax 30,000 30,000 각 단어별 발생 확률(0~1)로 변환 왜 마지막에 단어장 크기만큼 펼치나요?
모델이 내부에서 열심히 연산한 결과값($512$차원 벡터)은 숫자의 나열일 뿐, 그 자체로는 어떤 단어인지 알 수 없습니다. 이를 우리가 이해할 수 있는 "단어"로 바꾸기 위해 Linear Layer가 일종의 투표 용지를 만드는 역할을 합니다.
- 입력: $512$개의 특징 정보를 가진 벡터
- 출력: "우리 단어장에 있는 $30,000$개 단어 중 각각이 정답일 확률" (총 $30,000$개의 숫자)
출력 차원 30,000의 의미
- 인덱스(Index): $0$번부터 $29,999$번까지 각 칸은 단어장의 특정 단어와 1:1로 매칭되어 있습니다.
- 예: $0$번 = [PAD], $1$번 = [UNK], $105$번 = 사과, $2010$번 = Apple ...
- 점수(Logit): Linear Layer를 거친 직후에는 각 칸에 제각각의 점수(예: 사과 칸에는 $15.2$, 포도 칸에는 $1.1$)가 적힙니다.
- 확률(Probability): Softmax를 거치면 이 점수들이 "사과일 확률 98%", "포도일 확률 1%"처럼 변환됩니다.
흐름의 시작과 끝 (수수께끼 해결)
재미있는 점은 처음(Embedding)과 끝(Linear)이 단어장을 공유한다는 것입니다.
- 처음 (Input): 단어장에서 사과를 찾아 $105$번이라는 번호를 얻고, 이를 $512$차원 벡터로 바꿉니다.
- 중간 (Transformer): 문맥을 분석하며 벡터값을 수정합니다.
- 끝 (Output): 수정된 벡터를 다시 $30,000$개 칸으로 펼쳐서 "가장 높은 확률을 가진 번호가 뭐야?"라고 묻습니다. 만약 $105$번이 나오면 다시 단어장을 보고 "아, 정답은 사과구나!"라고 출력하는 것이죠.
Self-Attention
셀프 어텐션에서는 Q(Query), K(Key), V(Value)가 전부동일합니다.
Q : 입력 문장의 모든 단어 벡터들, K : 입력 문장의 모든 단어 벡터들, V : 입력 문장의 모든 단어 벡터들
셀프 어텐션에 대한 구체적인 사항을 배우기 전에 셀프 어텐션을 통해 얻을 수 있는 대표적인 효과에 대해서 이해해봅시다.

'그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.' 그런데 여기서 그것(it)에 해당하는 것은 과연 길(street)일까요? 동물(animal)일까요?
셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하므로서 그것(it)이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아냅니다
여기서 사용하고 있는 예문 중 student라는 단어 벡터를 Q, K, V의 벡터로 변환하는 과정을 보겠습니다.
가중치 행렬은 아래돠 같습니다, 이 가중치 행렬을 곱해서 3개의 Q, K, V가 나옵니다.
- $W^Q$ (Query 가중치): "어떤 정보를 질문(조회)할 것인가?"를 추출하는 필터.
- $W^K$ (Key 가중치): "어떤 특징을 꼬표(Label)로 내놓을 것인가?"를 추출하는 필터.
- $W^V$ (Value 가중치): "실제 전달할 정보의 알맹이는 무엇인가?"를 추출하는 필터.

임베딩 벡터 = 512, num_headers = 8 , 512 / 8 = 64
셀프 어텐션은 입력 입베딩 차원이 단어 벡터들을가지고 셀프어텐션을 수행하는것이 아니라, Q, K, V 벡터를 가지고 수행을합니다.
입력 데이터는 하나지만, 세 가지 다른 관점($Q, K, V$)으로 투영시켜서 사용한다는 의미입니다.
보통 512차원대신에 64차원을 자기는 3개의 벡터로 변환하는 과정입니다.
우선 입력된 단어 벡터들은 세 가지 서로 다른 성격의 벡터로 변신합니다.
- $Q$ (Query, 질의): 내가 찾고자하는정보
- $K$ (Key, 키): 단어가 가진특징 (대상/라벨)
- $V$ (Value, 값): "내가 가진 실제 정보의 알맹이는 이거야." (내용물)
사실 "저렇게 세 가지의 서로 다른 역할을 수행할 수 있도록 공간을 열어줬더니, 모델이 그 안에서 가장 효율적인 관계를 스스로 찾아내더라"가 더 정확한 설명입니다.
인코딩에서는 입력 문의 문맥적 의미 이해(masking 없음)를 하고 디코딩에서는 다음에 올 단어 예측합니다.
Scaled dot-product Attention
① 유사도 측정: $Q \times K^T$ (내적)
가장 먼저 내가 찾으려는 것($Q$)과 문장 내 모든 단어의 특징($K$)을 곱합니다.
- 설명
- 두 벡터를 내적한다는 것은 "방향이 얼마나 일치하는가?" 즉, 유사도를 측정하는 것입니다.
- 단어 하나하나가 가진 512개의 복잡한 특징(피쳐)들은 서로 곱해지고 더해지면서 사라집니다.
- 여기서 Q는 row, K는 열이 됩니다. 대신 그 피쳐들이 힘을 합쳐서 유사도를 나타내는 숫자 하나로 변신하는겁니다.
- I"라는 단어가 문장 내의 "I", "am", "a", "student"와 각각 얼마나 밀접한 관계인지 점수를 매깁니다.
- 결과: 'I'라는 단어의 $Q$가 'student'라는 단어의 $K$와 내적 값이 높다면, "둘은 문맥상 아주 밀접하다"는 점수(Attention Score)가 나옵니다.

② Attention Score: $\text{Scaling}$ ($\sqrt{d_k}$로 나누기)
여기서 트랜스포머만의 특징인 '스케일링'이 들어갑니다. 벡터의 차원($d_k$)이 커질수록 내적 값은 매우 커질 가능성이 높습니다
소프트맥스 함수의 특성상 가장 큰 값 하나가 다른 값들을 압도해버립니다.
- 현상
- 예를 들어 스케일링 전의 점수가 $[10, 20, 100]$이라면, 소프트맥스를 통과한 후에는 $[0.00004, 0.0001, \mathbf{0.9998}]$ 큰값 하나가 1을 독점
이렇게 되면 'student'라는 단어를 해석할 때 오직 자기 자신(100%)만 보고 주변 단어는 아예 무시하게 됩니다. 어텐션의 본래 목적인 "문맥 파악(주변 단어 참고)"이 불가능해지는 것이죠. - Embedding 차원 수가 깊어지면 깊어질수록 Dot-Product의 값은 커지게 되어 Softmax를 거치고 나면 미분 값이 작아지는 현상이 나타난다. 그 경우를 대비해 Scale 작업이 필요하다.
- 예를 들어 스케일링 전의 점수가 $[10, 20, 100]$이라면, 소프트맥스를 통과한 후에는 $[0.00004, 0.0001, \mathbf{0.9998}]$ 큰값 하나가 1을 독점
그래서 $\sqrt{d_k}$(예: 8)로 나누어 점수를 '진정시킵니다. $d_k = d_{model} / num_{heads}$ , 즉 512/8 = 64 값을 갖습니다.
③ Attention Distribution
어텐션 스코어에 소프트맥스 함수를 사용하여 어텐션 분포(Attention Distribution)을 구합니다.
- 결과: 모든 점수의 합이 1(100%)이 되도록 만듭니다.
- 의미: "I라는 단어를 해석할 때, 자기 자신에게 80%, student에 15%, am에 5%의 집중력을 배분하겠다"는 어텐션 분포(Attention Distribution)가 완성됩니다.
 ③ Attention ValueAttention Distribution에 V를 곱해서 모두 더해서 Attention Value를 만듭니다.
③ Attention ValueAttention Distribution에 V를 곱해서 모두 더해서 Attention Value를 만듭니다.- 설명: 관련 없는 단어의 $V$는 0에 가까운 값이 곱해져 사라지고, 관련 있는 단어의 $V$는 큰 비중으로 살아남습니다.
- 결과: 이것이 바로 컨텍스트 벡터(Context Vector)입니다. 단어 하나가 문장 전체의 문맥을 흡수한 '업그레이드된 벡터'가 되는 것이죠.
행렬 연산
사실 각 단어에 대한 Q, K, V 벡터를 구하고 스케일드 닷-프로덕트 어텐션을 수행하였던 위의 과정들은 벡터 연산이 아니라 행렬 연산을 사용하면 일괄 계산이 가능합니다.벡터 연산으로 설명하였던 이유는 이해를 돕기 위한 과정이고, 실제로는 행렬 연산으로 구현됩니다.
각각의 단어의 Q벡터와 K벡터의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나옵니다.

이렇게 되면 각 단어의 어텐션 값을 모두 가지는 어텐션 값 행렬이 결과로 나옵니다.
 $$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$- $QK^T$: "너랑 나랑 얼마나 친해?" (유사도)
- $/\sqrt{d_k}$: "너무 흥분하지 마, 점수 좀 깎자." (안정성)
- $\text{softmax}$: "누가 제일 중요한지 확률로 정해봐." (가중치)
- $\times V$: 그 비율대로 각 단어의 핵심 의미($V$)를 섞어서(더해서) 문맥을 완성해라!"
멀티 헤드 어텐션(Multi-head Attention)
"단어의 512개 특징을 64개씩 8팀으로 나눠서 각기 다른 관점으로 어텐션을 시킨 뒤, 나중에 다시 합치는 것"
- $d_{model} = 512$: 단어 하나가 가진 전체 정보량 (512차원)
- $num\_heads = 8$: 정보를 나누어 분석할 전문가(Head)의 수
- $d_k = 64$: 각 전문가 한 명이 담당하는 정보의 크기 ($512 / 8 = 64$)
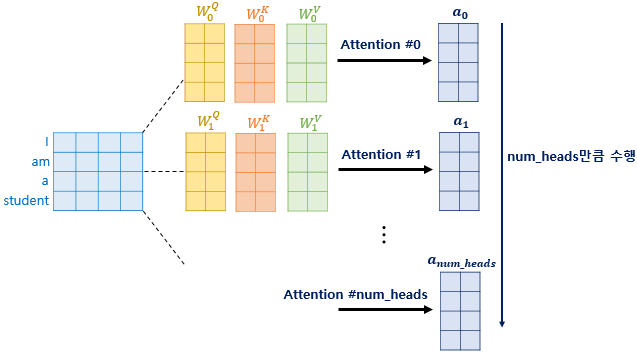
왜 굳이 나눠서 계산할까? (다각도 분석)
512차원을 통째로 한 명이 보는 것보다, 64차원씩 8명에게 맡기는 게 훨씬 유리합니다. 왜 그럴까요?
- 1번 전문가 (Head 1): "나는 이 단어의 문법적 관계만 볼게."
- 2번 전문가 (Head 2): "나는 이 단어의 의미적 유사성만 볼게."
- 3번 전문가 (Head 3): "나는 이 단어가 시간(과거/현재)과 관련 있는지 볼게."
만약 한 명(Single Head)이 512차원을 다 본다면 정보가 너무 섞여서 이런 디테일한 관계를 놓칠 수 있습니다. 하지만 8명으로 팀을 짜면 각자 다른 관점(Subspace)에서 문장을 훑어볼 수 있게 됩니다.
① 쪼개기 (Linear Projection)
512차원의 입력 행렬($X$)을 그대로 쓰는 게 아니라, 8세트의 가중치 행렬($W^Q, W^K, W^V$)을 각각 곱해줍니다.
- 결과적으로 64차원짜리 $Q, K, V$ 세트가 8개 만들어집니다.
- 비유: 512페이지짜리 두꺼운 보고서를 64페이지씩 8권으로 요약해서 8명의 전문가에게 나눠주는 것과 같습니다.
② 병렬 어텐션 (Parallel Attention)
8개의 헤드가 각자 독립적으로 우리가 아까 배운 '스케일드 닷-프로덕트 어텐션'을 수행합니다.
- 각 헤드($head_1 \dots head_8$)는 자기만의 점수판을 만들고, 자기만의 방식으로 $V$를 섞어서 결과를 냅니다.
- 이 과정은 GPU 안에서 동시(Parallel)**에 일어납니다.
③ 합치기 (Concatenate)
각 헤드가 연산을 마치고 가져온 64차원 결과물 8개를 옆으로 다시 찰떡같이 이어 붙입니다.
- 64차원 $\times$ 8개 = 512차원
- 다시 원래의 데이터 크기인 512차원으로 돌아왔습니다.
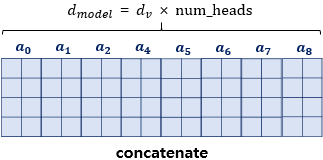
④ 최종 조율 (Final Linear)
마지막으로, 합쳐진 512차원 벡터에 또 다른 가중치 행렬($W^O$)을 곱합니다.
- 역할: 8명의 전문가가 각자 조사해온 결과물을 한데 모아 최종적인 결론으로 깔끔하게 정리하는 과정입니다.

1. 정보의 융합 (Feature Fusion)
8개의 헤드는 각각 다른 관점(문법, 의미, 거리 등)에서 어텐션을 수행했습니다.
- 문제: 헤드 1의 결과물(64차원)과 헤드 2의 결과물(64차원)은 서로 남남인 상태로 옆에 붙어 있습니다.
- 해결 ($W^O$): 이 512차원($64 \times 8$) 행렬에 $W^O$를 곱함으로써, 서로 다른 헤드들이 찾아낸 정보들을 유기적으로 섞어줍니다. "1번 헤드가 찾은 주어 정보와 3번 헤드가 찾은 동사 정보를 조합해보니 이런 결론이 나오네!"라고 최종 판단을 내리는 과정입니다.
2. 차원 유지 및 정제
트랜스포머는 여러 층(Layer)을 쌓아서 만듭니다.
- 규칙: 입력될 때 512차원이었으면, 출력될 때도 512차원이어야 다음 층으로 매끄럽게 넘어갈 수 있습니다.
- 역할: $W^O$는 [512 $\times$ 512] 크기의 행렬로서, 합쳐진 벡터의 크기를 유지하면서도 학습을 통해 가장 중요한 특징들만 다시 한 번 정제합니다.
3. 학습 가능한 파라미터
$W^Q, W^K, W^V$처럼 $W^O$ 역시 학습을 통해 변하는 파라미터입니다.
- 모델은 학습하면서 "아, 2번 헤드가 가져온 정보는 이번 문맥에서 별로 안 중요하니까 가중치를 낮추고, 5번 헤드 정보를 더 강조해야겠다"라는 식의 최종 조율법을 이 $W^O$ 행렬에 저장하게 됩니다.
마스크드 셀프 어텐션
인코더의 셀프 어텐션은 문장 전체를 한꺼번에 보고 각 단어 사이의 관계를 파악합니다. 하지만 디코더는 전개 방식이 다릅니다.
- 인코더: "I am a student" 전체를 동시에 참조 가능.
- 디코더: "나는", "학생", "입니다" 순서대로 단어를 하나씩 생성해야 함.
- 문제점: 학습 시에는 정답 문장 전체를 입력으로 주는데, 이때 모델이 현재 단어를 예측할 때 미래에 나올 단어(오른쪽 단어)를 미리 참조해버리면 학습이 제대로 이루어지지 않습니다. 이를 방지하기 위해 미래의 정보를 가리는(Masking) 작업이 필요합니다.
디코더는 실제 사용할 때(Inference)는 단어를 하나씩 만들지만, 학습할 때는 놀랍게도 모든 단어를 한꺼번에 처리합니다. 이를 이해하는 것이 트랜스포머의 핵심입니다.
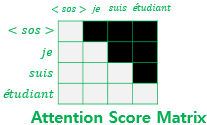
1. 어텐션 맵 생성 ($QK^T$)
먼저 쿼리($Q$)와 키($K$)를 내적하여 단어 간의 유사도를 구합니다. 이때 나오는 행렬이 바로 어텐션 맵입니다.
- 예: "I am a student" (4개 단어)
- 결과: $4 \times 4$ 크기의 행렬이 생성됩니다.
2. 마스킹 (Masking) 적용
이 $4 \times 4$ 행렬에서 현재 단어보다 미래에 있는 단어들의 위치를 찾아냅니다. (보통 행렬의 대각선 윗부분인 상삼각 행렬 영역입니다.)
그 자리에 아주 작은 음수값($-\infty$)을 강제로 집어넣습니다.
마스킹 전 스코어 (예시)
$$\begin{bmatrix} 12 & 8 & 5 \\ 7 & 11 & 9 \\ 4 & 6 & 13 \end{bmatrix}$$마스킹 후 스코어 (미래 시점 $-\infty$ 처리)
$$\begin{bmatrix} 12 & -\infty & -\infty \\ 7 & 11 & -\infty \\ 4 & 6 & 13 \end{bmatrix}$$3. 소프트맥스(Softmax) 통과
이제 이 행렬에 소프트맥스를 적용합니다. 소프트맥스 함수는 $e^x$를 기반으로 하므로, $e^{-\infty}$는 0이 됩니다.
최종 어텐션 가중치 (Softmax 결과)
$$\begin{bmatrix} 1.0 & 0 & 0 \\ 0.2 & 0.8 & 0 \\ 0.1 & 0.2 & 0.7 \end{bmatrix}$$이렇게 되면 세 번째 단어를 예측할 때, 첫 번째와 두 번째 단어의 정보는 가져올 수 있지만(0.1, 0.2), 아직 태어나지도 않은 미래의 단어 정보는 0이 되어 아예 참조할 수 없게 됩니다.
$$\text{Attention}(Q, K, V) = \text{Softmax}(\underbrace{\frac{QK^T}{\sqrt{d_k}}}_{\text{1. 스코어 계산}} + \underbrace{\text{Mask}}_{\text{2. 마스크 더하기}})V$$- 입력: [나는, 학생, 입니다] 전체가 동시에 입장
- 1층 (Masked Self-Attention): 마스크 덕분에 각 단어는 자기 미래를 보지 못한 채 동시에 처리됨
- 1층 (Cross Attention): 이 3개의 벡터가 동시에 인코더를 조회
- 최종 출력: [Next of 나는(->학생), Next of 학생(->입니다), Next of 입니다(->[EOS])]가 동시에 출력됨

Cross Attention: 인코더-디코더 어텐션
디코더의 두번째 서브층 : Query : 디코더 행렬 / Key = Value : 인코더 행렬어텐션을 '검색'에 비유하면 이 문장의 의미가 바로 이해됩니다.
- Query (질문자) = 디코더 행렬:
- "지금 내가 '나는'까지 말했는데, 그다음에 무슨 단어를 써야 하지? 원문(인코더) 중에 참고할 만한 정보 있어?"라고 질문을 던지는 주체입니다.
- 디코더의 첫 번째 층(Masked Self-Attention)을 통과하며 현재까지 생성된 문맥을 파악한 벡터들입니다.
- Key & Value (정보 제공자) = 인코더 행렬:
- Key: 인코더가 분석한 원문 단어들의 '이름표' (예: "I", "am", "a", "student" 각각의 특징)
- Value: 그 이름표가 가진 실제 '의미 정보'
- 인코더의 맨 마지막 층에서 나온 최종 출력값입니다.
Query가 디코더 행렬, Key가 인코더 행렬일 때, 어텐션 스코어 행렬을 구하는 과정은 다음과 같습니다.

그 외에 멀티 헤드 어텐션을 수행하는 과정은 다른 어텐션들과 같습니다.
ADD & Norm
Residual Connection(잔차 연결)
잔차 연결은 아주 단순한 아이디어입니다. "입력값을 가공한 결과($F(x)$)에 입력값($x$)을 그대로 더해버리자!"는 것입니다.
그러니까, 이전과 비교해서 attention 된 것만 학습하겠다는 의미입니다.
$$Output = x + F(x)$$- 기울기 소실 방지: 층이 깊어지면 미분값이 0에 가까워져 학습이 안 되는 문제가 생깁니다. 하지만 더하기($+$) 연산은 미분해도 $1$이 남기 때문에, 아무리 층이 깊어도 정보(기울기)가 맨 앞 층까지 막힘없이 전달됩니다.
- 원본 유지: $F(x)$(어텐션이나 FFN)가 데이터를 너무 많이 변형시키더라도, 원래 정보($x$)가 더해져 있기 때문에 모델이 길을 잃지 않습니다. "공부한 내용($F(x)$)에 원래 알고 있던 내용($x$)을 보태서 기억한다"고 보시면 됩니다.
Norm: 레이어 정규화 (Layer Normalization)
잔차 연결로 값을 더하고 나면 숫자가 너무 커지거나 들쭉날쭉해질 수 있습니다.
값들의 분포가 쏠려 있을수 있습니다. 그 쏠려있는 범위에서만 모델은 변별력이 가져서, 전체적인 변별력이 없어집니다.
이를 예쁘게 다듬어주는 것이 Layer Norm입니다.$$LayerNorm(x + F(x))$$
- 단어별 정규화: 한 문장 안에서 각 단어 벡터들의 평균과 분산을 계산하여, 모든 벡터가 일정한 범위 내의 값을 갖도록 조정합니다.
- 학습 안정화: 특정 수치가 너무 튀지 않게 잡아주어 학습 속도를 높이고 성능을 안정화합니다.
Position-wise FFN(Feed Forword Network)
트랜스포머의 각 층에 포함된 이 네트워크는 아주 단순한 두 개의 선형 층(Linear Layer)과 그 사이의 활성화 함수(ReLU 또는 GeLU)로 구성된 신경망입니다. 그냥 비선형성을 해준다는 개념입니다.
수식으로는 보통 다음과 같이 표현됩니다:
$$FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2$$- 첫 번째 선형 층 ($W_1$): 입력 벡터의 차원을 확 키웁니다. (보통 512차원에서 2048차원으로 4배 정도 확장)
- 활성화 함수 (ReLU/GeLU): 비선형성을 추가하여 모델의 표현력을 높입니다.
- 두 번째 선형 층 ($W_2$): 다시 원래 차원(512)으로 줄입니다.
왜 필요한가? (핵심 역할)
- 개별 단어의 "의미 정제"
- 어텐션은 다른 단어들과의 관계를 계산하느라 정보가 섞인 상태입니다. FFN은 이 섞인 정보를 바탕으로 각 위치(Position)에서 독자적으로 정보를 재가공합니다. 어텐션이 '연결'이라면, FFN은 '개인 학습' 시간입니다.
- "Position-wise" (위치별 처리)
- FFN의 가장 큰 특징은 모든 단어에 똑같은 가중치가 적용되지만, 각 단어는 서로 독립적으로 계산된다는 점입니다.
- "나는"이라는 단어와 "학생"이라는 단어는 똑같은 $W_1, W_2$를 통과하지만, 서로 영향을 주지 않고 자기 갈 길을 갑니다.
- 똑같은 층의 FFN의 $W_1, W_2$는 같습니다.
- 커널 사이즈가 1인 Convolution을 두 번 연산한 것과 동일하다고 합니다.
한 단어를 Embedding 차원만큼의 채널을 갖는 이미지라고 취급한다면 이해가 되실 겁니다. Convolution 레이어의 Weight는 [입력 차원 수 X 출력 차원 수 X 커널의 크기] 이므로 커널의 크기가 1이라면 Linear 레이어와 동일한 크기의 Weight를 갖게 되죠

구분 Linear Layer 1x1 Convolution Layer 대상 숫자 리스트 (벡터) 한 칸짜리 이미지 가중치 공식 입력 $\times$ 출력 입력 $\times$ 출력 $\times$ 커널크기(1) 결과 $512 \times 2048$ $512 \times 2048$ - 모델의 "지식 저장소"
- 최근 연구들에 따르면, 트랜스포머의 학습된 '지식'이나 '패턴' 중 상당 부분이 어텐션이 아닌 이 FFN의 가중치에 저장된다는 분석이 많습니다.
어텐션(Attention) = "데이터 수집 및 통합"
어텐션을 거치면 각 단어 벡터는 주변 단어들의 정보를 골고루 나눠 가집니다.
- 상황: 'Bank'라는 단어가 있을 때, 주변에 'River'가 있는지 'Money'가 있는지 보고 그 정보를 'Bank' 벡터 안에 섞어 넣습니다.
- 결과: 이제 'Bank' 벡터 안에는 "나 주변에 'Money'도 있어!"라는 관계 정보가 포함됩니다. 하지만 정보들이 그냥 비빔밥처럼 섞여만 있는 상태입니다.
FFN = "개별 데이터 가공 및 특징 추출"
이제 섞여 들어온 정보들을 바탕으로 이 단어의 최종 의미가 무엇인지 결론을 내야 합니다.
- 작동: 다른 단어는 신경 안 쓰고, 오직 내 벡터($1 \times 512$)만 쳐다보며 복잡한 비선형 연산($W_1 \rightarrow ReLU \rightarrow W_2$)을 수행합니다.
- 비유 (개인 학습): "자, 아까 어텐션 시간에 친구들(주변 단어)이랑 얘기해서 정보 많이 모았지? 이제 조용히 혼자서(FFN) 그 정보들을 종합해 봐. 그래서 네 진짜 의미가 '은행'이야, '둑'이야?"라고 처리하는 과정입니다.
리니어(Linear) 층: "단어장 크기로 투사"
디코더의 마지막 블록을 나온 결과물은 여전히 추상적인 숫자 벡터(예: 512차원)입니다. 하지만 우리가 가진 단어장(Vocabulary)에는 수만 개의 단어가 있죠.
- 역할: 512차원의 벡터를 단어장의 전체 크기(예: 30,000개)만큼의 차원으로 확 늘려버립니다.
- 의미: 이 연산을 거치고 나면 30,000개의 칸이 생기는데, 각 칸의 숫자는 "이번 차례에 이 단어가 나올 확률이 얼마나 높은가?"에 대한 점수(Logit)가 됩니다.
- 예: '학생' 위치의 칸은 15.2점, '사과' 위치의 칸은 -2.1점... 이런 식입니다
행렬 곱 연산 ($W \cdot x + b$)
마지막 층인 Linear Layer(Dense Layer)에는 모델이 학습을 통해 얻은 거대한 가중치 행렬이 들어있습니다.
- 입력 벡터 ($x$): 512차원
- 가중치 행렬 ($W$): $30,000 \times 512$ 크기의 행렬
- 연산: $1 \times 512$ 크기의 벡터와 $512 \times 30,000$ 크기의 가중치 행렬을 곱합니다.
- 결과: 그 결과로 30,000차원의 새로운 벡터가 탄생합니다.
점수(Logit)의 의미
이렇게 확장된 30,000개의 각 칸에는 숫자들이 채워집니다.
- 이 숫자들은 "현재 위치에 단어장의 $n$번째 단어가 올 확률이 얼마나 높은가"를 나타내는 점수(Logit)입니다.
- 예를 들어, 100번째 칸의 숫자가 매우 높다면, 모델은 단어장의 100번째 단어(예: 'student')가 정답일 가능성이 높다고 판단하는 것입니다.
왜 하필 단어장 크기인가요?
- 우리가 사용하는 모든 단어는 사전에 번호가 매겨져 있습니다.
- 만약 단어장이 30,000개라면, 모델은 30,000개의 후보 중 하나를 골라야 하는 '다중 분류' 문제를 풀어야 합니다.
- 따라서 최종 출력은 반드시 우리가 비교하고자 하는 대상(단어장)의 개수와 일치해야만 합니다
소프트맥스(Softmax) 층: "점수를 확률로 변환"
리니어 층에서 나온 점수들은 제각각(음수일 수도, 아주 클 수도)이라서 직접 사용하기 어렵습니다. 이를 0에서 1 사이의 확률값으로 바꾸고, 전체 합이 1(100%)이 되도록 만듭니다.
- 계산: 점수가 높을수록 확률이 지수적으로 커지게 만듭니다.
- 결과:
- "학생": 0.85 (85%)
- "학교": 0.10 (10%)
- "사과": 0.01 (1%)
- ... (나머지 단어들 합쳐서 0.04)
학습률 스케줄러(Learning Rate Scheduler)
트랜스포머를 훈련하는 데에는 Adam Optimizer를 사용했는데, 특이한 점은 Learning Rate를 수식에 따라 변화시키며 사용했다는 것입니다. 수식은 아래와 같습니다.
$$lrate = d_{model}^{-0.5} \cdot \min(step\_num^{-0.5}, step\_num \cdot warmup\_steps^{-1.5})$$여기서 각 변수의 의미는 다음과 같습니다.
- $d_{model}$: 모델의 임베딩 차원 (예: 512). 모델이 클수록 학습률의 전체적인 크기를 줄여주는 역할을 합니다.
- $step\_num$: 현재 학습이 진행된 단계(Step) 번호입니다.
- $warmup\_steps$: 학습률을 끌어올리는 구간의 길이(예: 4000)입니다.
2. 두 가지 단계 (The Two Phases)
수식에서 min 함수를 사용하기 때문에, 학습은 크게 두 단계로 나뉩니다.
① 웜업 단계 (Warmup Phase)
학습 초기($step\_num < warmup\_steps$)에는 min 함수 내부에서 뒤쪽의 값($step\_num \cdot warmup\_steps^{-1.5}$)이 더 작습니다.
- 이때 학습률은 $step\_num$에 비례하여 선형적으로 증가합니다.
- 이유: 학습 초기에는 가중치가 무작위로 초기화되어 있어 그래디언트(Gradient)가 매우 불안정합니다. 이때 너무 큰 학습률을 적용하면 모델이 발산해 버릴 수 있으므로, 아주 작은 값부터 서서히 높여가며 모델을 안정적으로 '예열'하는 과정입니다.
② 감쇠 단계 (Decay Phase)
웜업이 끝난 후($step\_num > warmup\_steps$)에는 앞쪽의 값($step\_num^{-0.5}$)이 더 작아집니다.
- 이때 학습률은 단계의 제곱근에 반비례($1/\sqrt{step}$)하여 서서히 감소합니다.
- 이유: 학습이 어느 정도 진행된 후에는 최적의 지점(Local Minimum)에 정교하게 도달해야 합니다. 학습률을 점점 줄여줌으로써 오차 함수(Loss function)의 바닥으로 부드럽게 수렴하게 만듭니다.
3. $d_{model}^{-0.5}$의 의미
이 상수는 모델의 크기에 따른 스케일링을 담당합니다.
- 트랜스포머는 차원($d_{model}$)이 커질수록 어텐션 스코어나 그래디언트의 절대적인 크기가 커지는 경향이 있습니다.
- 이를 보정하기 위해 차원의 제곱근으로 나누어줌으로써, 모델의 크기가 달라져도 학습이 일관성 있게 진행되도록 돕습니다.
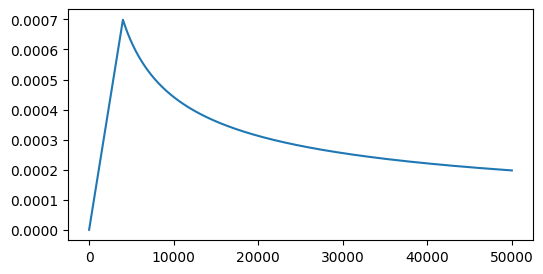
- 초반 (0~4000): 산을 등반하듯 직선으로 빠르게 올라갑니다.
- 정점 (4000): 가장 높은 학습률에 도달합니다.
- 후반 (4000~50000): 미끄럼틀을 타듯 완만하게 곡선을 그리며 내려갑니다.
'AI' 카테고리의 다른 글
NLP 데이터 증강 (1) 2026.03.06 [NLP 아키텍처 연대기] 통계에서 트랜스포머까지: 언어 이해의 여정 (1) 2026.03.02 Seq2Seq의 한계를 넘어서: Attention 메커니즘 (0) 2026.02.23 LSTM(Long Short-Term Memory) (1) 2026.02.22 순환 신경망(RNN)의 개념 (0) 2026.02.22