-
텍스트 벡터화(Text Vectorization)AI 2026. 2. 20. 16:22
컴퓨터는 '언어'를 읽지 못합니다. 컴퓨터에게 언어란 오직 '숫자'일 뿐이죠. 우리가 책을 읽고 감동을 받는 과정을 컴퓨터에게 시키려면, 먼저 글자를 좌표 평면 위의 숫자로 바꾸어 주어야 합니다. 이 과정을 벡터화라고 합니다.
전통적 방식: 통계 기반의 "단어 세기"
초기 모델들은 단어의 의미보다는 "어떤 단어가 얼마나 자주 나왔나?"에 집중했습니다.
① BoW (Bag of Words)
- 비유: 문장을 믹서기에 넣고 갈아서 단어들만 남긴 봉투입니다.
- 한계: "내가 너를 사랑해"와 "너가 나를 사랑해"는 구성 단어가 같아 BoW에선 똑같은 문장으로 취급됩니다. 순서와 문맥이 완전히 사라지기 때문이죠.
- 예제
- 여기 세 개의 문장이 있다고 가정해 보겠습니다.
문장 1: "나는 사과가 좋다"
문장 2: "나는 포도가 좋다"
문장 3: "나는 사과가 정말 정말 좋다" - 1단계: 단어사전 만들기
먼저 중복을 제거하고 등장한 모든 단어를 모아 번호를 매깁니다. (조사 등은 편의상 그대로 두겠습니다.)번호 단어 1 나는 2 사과가 3 포도가 4 좋다 5 정말 - 2단계: 문장별 단어 빈도수 세기
이제 각 문장에서 해당 단어가 몇 번 등장했는지 숫자를 적습니다.
문장 1 ("나는 사과가 좋다"): - 나는(1), 사과가(1), 포도가(0), 좋다(1), 정말(0)
결과: [1, 1, 0, 1, 0]
문장 2 ("나는 포도가 좋다"): - 나는(1), 사과가(0), 포도가(1), 좋다(1), 정말(0)
결과: [1, 0, 1, 1, 0]
문장 3 ("나는 사과가 정말 정말 좋다"): - 나는(1), 사과가(1), 포도가(0), 좋다(1), 정말(2)
결과: [1, 1, 0, 1, 2] - 최종결과(문서-단어행렬, DTM)
이것을 표로 정리하면 우리가 머신러닝 모델에 집어넣을 수 있는 숫자 데이터가 됩니다.구분 나는 사과가 포도가 좋다 정말 문장 1 1 1 0 1 0 문장 2 1 0 1 1 0 문장 3 1 1 0 1 2
- 여기 세 개의 문장이 있다고 가정해 보겠습니다.
② DTM (Document-Term Matrix)
- BoW를 여러 문서에 대해 표(Matrix)로 만든 것입니다
- 개선점:"문서 간 비교를 위한 규격화"
- 문서 간 유사도 계산: 행(문서)과 행(문서) 사이의 거리를 계산할 수 있게 되어, "어떤 문서들이 서로 내용이 비슷한가?"를 수학적으로 비교할 수 있게 되었습니다.
- 단어 중요도 파악: 열(단어)을 세로로 쭉 보면, 이 단어가 전체 문서군에서 얼마나 자주 쓰이는지 한눈에 보입니다. (이후 TF-IDF의 기반이 됩니다.)
- 머신러닝 입력 최적화: 모델에 데이터를 넣을 때 "규격화된 표" 형태가 필요합니다. DTM은 여러 문서를 하나의 행렬 데이터셋으로 규격화해 줍니다.
- 문제점
- 희소성(Sparsity)세상에 단어가 10만 개라면, 고작 5단어로 이루어진 문장 하나를 표현하기 위해 99,995개의 '0'을 적어야 합니다. 메모리 낭비가 엄청나죠. - 차원의 저주
- 직교성과 거리 문제: 원-핫 인코딩(One-hot Encoding) 방식으로 단어를 표현하면 모든 단어 벡터가 서로 직교하게 됩니다. 이 경우 내적값이 0이 되어, 단어 간의 유클리드 거리가 항상 $\sqrt{2}$로 동일해집니다. 즉, 단어 간의 유사도나 가깝고 먼 관계를 전혀 측정할 수 없습니다.
- 불용어(Stopwords) 문제: '는', '이', '가', 'the', 'a' 같은 단어들은 모든 문서에서 압도적으로 많이 등장합니다. DTM 입장에서는 이 단어들이 빈도가 높으니 "가장 중요한 핵심어"라고 착각하게 됩니다.
- 변별력 상실: 모든 문서에 공통적으로 등장하는 단어는 해당 문서를 구분 짓는 특징이 될 수 없습니다. 하지만 DTM은 이를 걸러내지 못합니다.
③ TF-IDF (가장 많이 쓰이는 전통 방식)
단순 빈도수(불용어,변별력 상실) 의 함정을 피하기 위한 기술입니다.단어의 '단순 빈도'가 아닌 '상대적 중요도'를 계산하는 로직"을 개선
- TF (Term Frequency): 특정 문서에 단어가 많이 나오면 중요함.
- DF (Document Frequency, 문서 빈도): 특정 단어가 등장한 '문서의 개수', 높을수록 흔혼용어라서 중요도하락
- IDF (Inverse Document Frequency): 그런데 그 단어가 모든 문서(‘는’, ‘이’, ‘가’ 등)에 다 나오면 그건 흔한 말일 뿐이니 중요도를 깎음.
$$IDF(d, t) = \log\left(\frac{N}{DF(t)}\right)$$
- N 전체 문서의 개수
- DF가 커질수록(분모가 커질수록): 전체 값인 IDF는 작아집니다. (예: '는', '이', '가')
- DF가 작아질수록(분모가 작아질수록): 전체 값인 IDF는 커집니다. (예: '임베딩', '역전파')
- 로그를 취하는 이유는 :엄청난 숫자 차이 완화 (스케일 조정), 희귀 단어'에 과도한 보너스 방지
$$\text{TF-IDF} = \text{TF} \times \text{IDF}$$- TF (Term Frequency): 단어 빈도 (한 문서 안에서 많이 나오면 높은)
- IDF (Inverse Document Frequency): 역문서 빈도 (여러 문서에 안 나올수록 높음)
- 결과: 특정 문서에서만 유독 많이 등장하는 단어에 높은 점수를 주어 키워드 추출에 탁월합니다.
앞서 보았던 DTM(단순 빈도)은 정수(1, 2, 0...)로 결과가 나왔지만, TF-IDF의 출력은 0과 1 사이의 실수(Float)로 이루어진 '가중치 벡터'가 됩니다.
문장 1: "나는 사과가 좋다"
전체 단어 사전: [나는, 사과가, 포도가, 좋다, 정말]
구분 나는 사과가 포도가 좋다 정말 DTM (빈도) 1 1 0 1 0 TF-IDF (상대적중요도) 0.12 0.45 0 0.12 0
현대적 방식: 의미 기반의 "임베딩(Embedding)"
"현대적 NLP는 단어를 단순 '빈도'가 아닌 고차원 '공간 내 좌표'로 표현합니다. 이를 밀집 표현(Dense Representation) 또는 분산 표현(Distributed Representation)이라 부릅니다. 고정된 규칙에 따라 값을 부여하는 원-핫 인코딩(One-hot Encoding)과 달리, 임베딩(Embedding)은 모델이 데이터를 통해 단어 간의 의미적 유사성을 직접 학습하며 최적의 수치값을 찾아가는 과정입니다.
분포 가설 (Distributional Hypothesis)
- 핵심 아이디어: "비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다."
- 임베딩의 가장 기초가 되는 철학적 가설입니다. 1957년 언어학자 존 퍼스(J.R. Firth)는 *"단어의 의미는 그 옆에 어울리는 단어를 보면 알 수 있다"*고 말했습니다.
- 예를 들어, "나는 사과를 먹는다"와 "나는 포도를 먹는다"라는 문장에서 '사과'와 '포도'는 '먹는다'라는 동일한 주변 환경을 가집니다. 이를 통해 컴퓨터는 "아, 사과와 포도는 비슷한 부류구나!"라고 가정하게 됩니다
동시 발생 (Co-occurrence)
- 핵심 아이디어: "단어들이 얼마나 자주 함께 나타나는가?"
- 분포 가설을 '수치'로 증명하는 방식입니다. 특정 단어 주변에 어떤 단어들이 주로 나타나는지 그 빈도를 계산합니다.
- 동시 발생 행렬 (Co-occurrence Matrix): 문장 전체를 훑으며 '사과'와 '먹는다'가 몇 번 같이 나왔는지 표로 기록합니다.
- 이 방식은 전통적 통계 방식에서도 쓰였지만, 현대 딥러닝(GloVe 등)에서도 이 정보를 활용해 단어의 의미적 거리를 좁힙니다. 즉, 동시 발생 빈도가 높을수록 공간상에서 가깝게 배치하게 됩니다.
왜 '분산 표현'인가?
단어의 의미를 여러 차원에 잘게 쪼개어 분산시킨다는 뜻입니다. 예를 들어 '사과'라는 단어를 [빨갛다: 0.9, 과일: 0.8, 형태: 0.5] 처럼 저차원의 밀집 벡터(Dense Vector) 안에 실수로 빼곡히 채우는 방식입니다.
- 장점: 단어 간의 유사도를 측정할 수 있고, 관계 유추가 가능해집니다. 그 유명한 $King - Man + Woman = Queen$ 연산이 가능해지는 마법이 여기서 일어납니다.
밀집 벡터의 실수는 "이 단어는 어떤 성질을 얼마나 가지고 있니?"를 나타내는 게이지(Gauge)입니다.
- 1차원: '생명체인가?' (높을수록 생물)
- 2차원: '기계인가?' (높을수록 기계)
- 3차원: '먹을 수 있는가?' (높을수록 음식)
이때 단어들은 아래와 같은 실수 값을 가질 수 있습니다.
단어 1차원 (생물) 2차원 (기계) 3차원 (식품) 벡터 표현 강아지 0.98 0.01 0.05 [0.98, 0.01, 0.05] 사과 0.85 0.02 0.95 [0.85, 0.02, 0.95] 노트북 0.01 0.99 0.02 [0.01, 0.99, 0.02] 임베딩 스페이스(Embedding Space)는 방금 우리가 만든 그 '분산 표현' 벡터들이 실제로 살고 있는 가상의 다차원 공간을 말합니다.
쉽게 말해, 우리가 단어를 실수 뭉치(벡터)로 변환하는 순간, 그 단어들은 종이 위가 아니라 좌표 평면 위로 점을 찍으며 날아갑니다. 그 점들이 모여서 이루는 전체 우주가 바로 임베딩 스페이스입니다.
1. 지도로 비유하기
- 단어: 특정 도시 (예: 서울, 부산, 도쿄)
- 분산 표현(벡터): 그 도시의 위도와 경도 좌표 (예: [37.5, 126.9])
- 임베딩 스페이스: 그 좌표들이 찍혀 있는 세계 지도 전체
우리가 앞서 만든 표를 공간으로 옮기면 이렇게 됩니다.
- 1차원(생물), 2차원(기계), 3차원(식품)이 각각 X축, Y축, Z축이 되는 3차원 공간이 생깁니다.
- 강아지는 $(0.98, 0.01, 0.05)$ 지점에 점이 찍히고,
- 사과는 $(0.85, 0.02, 0.95)$ 지점에 점이 찍힙니다.
- 이 점들이 찍혀 있는 그 3차원 공간 자체가 임베딩 스페이스입니다.
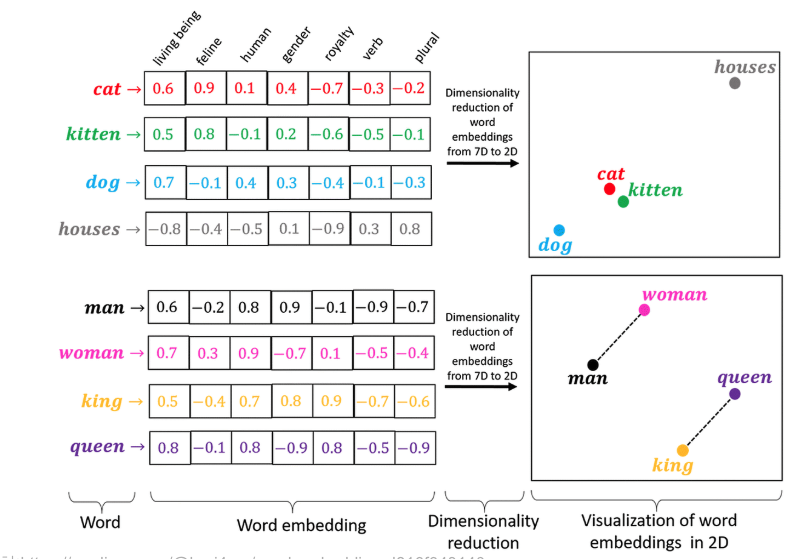
💡 핵심 기술: 단어 사이의 거리를 재는 '코사인 유사도'
단어를 좌표로 만들었다면, 이제 두 단어가 얼마나 유사한지 측정할 방법이 필요합니다. 이때 가장 많이 사용하는 것이 바로 코사인 유사도(Cosine Similarity)입니다.
- 작동 원리: 가중치 행렬 $W$에서 두 단어의 행(벡터)을 꺼내와, 두 벡터 사이의 각도를 측정합니다.
- 수식:
$$\text{Similarity} = \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|}$$ - 의미: > * 결과가 1에 가까우면: 두 벡터가 같은 방향을 가리킴 → 매우 유사함 (예: 강아지 - 멍멍이)
- 결과가 0에 가까우면: 두 벡터가 직교함 → 관계없음
- 결과가 -1에 가까우면: 두 벡터가 반대 방향임 → 반대 의미
단순히 유클리드 거리(직선 거리)를 재는 것보다 코사인 유사도를 선호하는 이유는, 벡터의 길이보다 '방향성'이 단어의 의미적 유사성을 더 잘 나타내기 때문입니다.
Word2Vec: 예측이 통계를 이긴 이유
통계 기반 방식(TF-IDF 등)은 단순히 빈도를 기록할 뿐 가중치를 업데이트하는 '학습' 과정이 없습니다. 반면, Word2Vec은 '예측'을 통해 백 프로파게이션(Back-propagation)을 수행하며 가중치를 업데이트합니다.
- 장점: 단어가 늘어나도 벡터의 크기(차원)를 고정할 수 있어 연산에 유리하며, '레이턴트 스페이스(Latent Space)'를 통해 문맥적 의미를 파악합니다.
FastText: Word2Vec의 한계를 넘어서
Word2Vec도 완벽하진 않았습니다. 사전에 없는 단어인 OOV(Out of Vocabulary) 문제를 해결하지 못했기 때문이죠. 이를 개선한 것이 페이스북의 FastText입니다.
- 핵심 아이디어 - Subword: 단어를 더 작은 단위인 n-gram으로 쪼개어 학습합니다.
- 예: 'apple'을 <ap, app, ppl, ple, le> 등으로 분해.
- 강점: 모르는 단어가 나와도 그 안에 포함된 n-gram들의 조합을 통해 의미를 유추할 수 있습니다. 오타가 있거나 복합어가 많은 한국어 처리에서도 매우 강력한 성능을 발휘합니다.
⚠️ 하지만 여전한 숙제: "고정 벡터"의 한계
지금까지 살펴본 Word2Vec이나 FastText 같은 워드 임베딩 방식들은 아주 혁신적이지만, 결정적인 치명타가 하나 있습니다. 바로 **'다의어'**를 구분하지 못한다는 점입니다.
예시) "차"라는 단어의 세 가지 의미
- 시간이 늦었으니 커피 말고 차(Tea)나 한 잔 마시자.
- 제주도는 버스로 움직이기 힘들어. 차(Car)가 있어야 해.
- 축구공을 이쪽으로 차(Kick).
이제 어떤 문제가 발생하는지 감이 오시나요? 워드 임베딩 방법들은 학습할 때는 주변 단어를 열심히 보지만, 학습이 끝난 뒤 모델의 입력값으로 사용할 때는 동음이의어나 다의어를 모두 고정된 하나의 벡터로만 표현합니다.
정작 학습할 때는 문맥을 열심히 보더니, 실제 테스트(사용)할 때는 주변 단어를 보지 않고 현재 단어 하나만 보고 사전에서 값을 꺼내오는 모양새가 되어버린 것이죠.
💡 해결책: 문맥을 고려하는 임베딩 (Contextual Embedding)
똑똑한 여러분은 '문맥을 고려하는 임베딩을 만들면 되지 않나?!'라고 생각하실 겁니다. 네, 맞습니다! 바로 다음에 등장하는 모델들(ELMo, BERT, Transformer)은 이러한 문맥(Context)을 실시간으로 반영하여, 똑같은 "차"라도 문장에 따라 매번 다른 숫자로 변신시키는 똑똑한 모델들입니다.
한눈에 비교하는 요약 테이블
구분 통계 기반 (BoW, DMT, TF-IDF) - 인코딩 임베딩 (Word2Vec, FastText) 표현 방식 희소 표현 (대부분이 0)- 수동적 수동적 성격: 어떤 단어에 어떤 인덱스를 줄지는 사람이 만든 사전의 순서 밀집 표현 (숫자가 꽉 참) 자동 - 처음에는 무작위 실수로 시작했다가, 수많은 문장을 읽으며 "사과와 포도는 가까워야 해!"라고 판단하면 좌표를 스스로 수정합니다. 차원(크기) 단어 종류가 많아질수록 무한 확장 사용자 설정 (보통 100~300차원) 의미 반영 못함 (단어 형태가 다르면 남남) 잘함 (유사어, 반의어 파악 가능) 주 사용처 가벼운 분류, 키워드 분석 복잡한 챗봇, 번역기, 감성 분석 'AI' 카테고리의 다른 글
Word2Vec: Negative Sampling (0) 2026.02.21 단어의 의미를 벡터로, Word2Vec (0) 2026.02.21 토큰화(Tokenization)의 진화: 단어에서 서브워드까지 (1) 2026.02.20 텍스트 데이터의 특징과 자연어 처리 파이프라인 완벽 이해 (0) 2026.02.20 이미지 인식의 핵심: Inductive Bias, Locality, 그리고 특징 추출의 상관관계 (0) 2026.02.20