-
이미지 인식의 진화: AlexNet에서 VGG16, 그리고 1x1 Conv의 마법까지AI 2026. 2. 5. 10:25
미지 인식 모델의 근간을 이룬 두 주인공, AlexNet과 VGG16의 구조적 차이를 분석하고, 현대 CNN 구조에서 '약방의 감초' 역할을 하는 1x1 Convolution의 정체에 대해 자세히 정리해 보겠습니다.
모델이 "깊어진다"와 "넓어진다"의 의미
모델의 성능을 높이기 위해서는 구조를 복잡하게 만들어야 합니다. 이때 방향은 두 가지입니다.
- 깊어진다 (Deeper): Layer(층)를 더 높게 쌓는 것입니다. 층이 깊어질수록 모델은 '점 → 선 → 면 → 눈/코/입 → 얼굴 전체'와 같이 단계별로 데이터의 추상적인 특징(Abstract Features)을 계층적으로 학습합니다.
- 넓어진다 (Wider): 각 Layer 내의 Channel(Filter) 수를 늘리는 것입니다. 한 번에 수용할 수 있는 정보의 양이 많아져 색상, 질감, 각도 등 다양한 특징을 병렬적으로 동시에 추출할 수 있습니다.
※ 장단점 요약
- 장점: 표현력(Expressiveness)이 좋아져 복잡한 데이터도 척척 분류합니다.
- 단점: 과적합(Overfitting) 위험이 커지고, 연산량(Memory)이 폭증하며, 층이 너무 깊으면 신호가 사라지는 기울기 소실(Vanishing Gradient) 문제가 발생합니다.
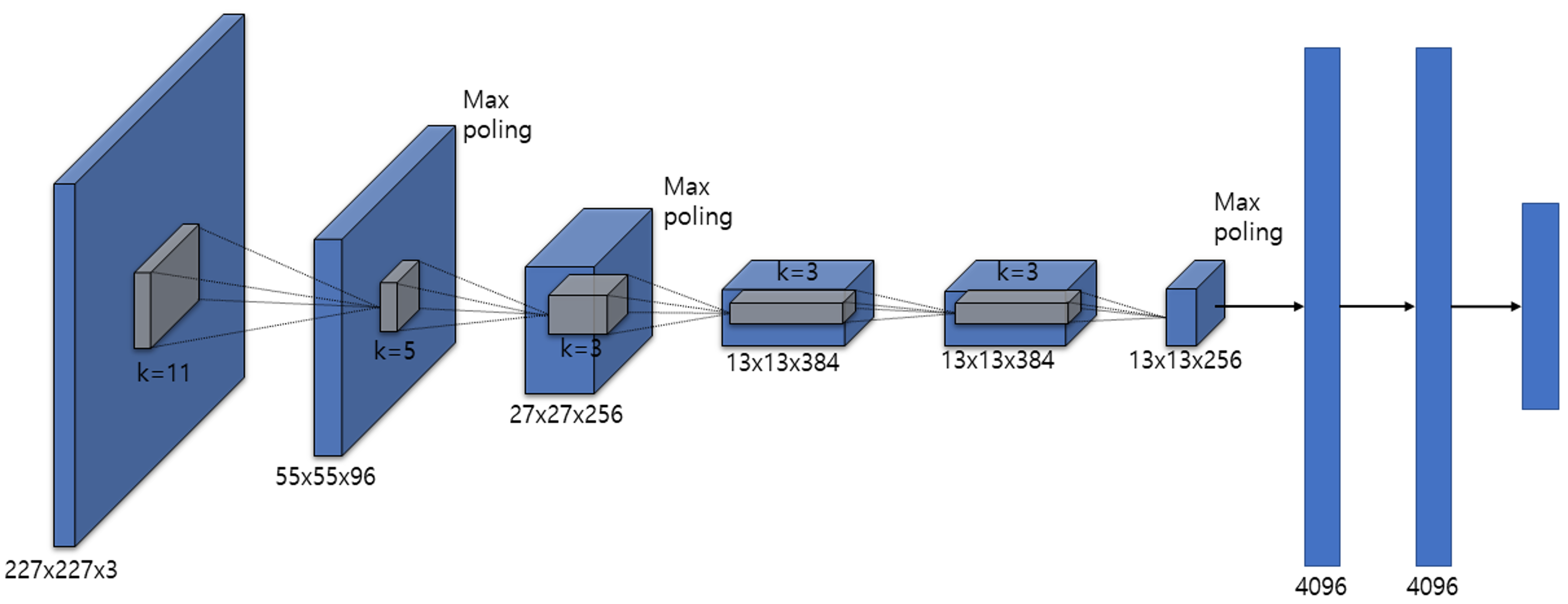
AlexNet vs VGG16: "작게, 그리고 깊게"의 승리
두 모델은 모두 Conv → Pooling → ReLU라는 기본 유닛을 공유하지만, 성능은 VGG16이 압도적(오류율 약 10% 차이)입니다. 그 비결은 무엇일까요?
① 필터 사이즈 (Filter Size): "크게 한 번 vs 작게 여러 번"
- AlexNet: $11 \times 11$, $5 \times 5$ 같은 대형 필터를 사용하여 초반에 넓은 영역을 한꺼번에 보려 했습니다.
- VGG16: 오직 $3 \times 3$ 필터만 고집합니다.
- 연산 효율: $5 \times 5$ 필터 1개의 파라미터가 25개일 때, $3 \times 3$ 필터 2개는 18개($9 \times 2$)입니다. 파라미터 수는 줄이면서 모델은 더 깊게 만들 수 있는 비결입니다.
② 수용 영역 (Receptive Field): "결과는 같지만 과정은 정교하게"
$3 \times 3$ 필터를 두 번 쌓으면 $5 \times 5$ 필터 한 개와 동일한 영역을 커버하게 됩니다. 세 번 쌓으면 $7 \times 7$과 같아지죠. 즉, VGG는 AlexNet이 큰 필터로 듬성듬성 보던 영역을 작은 필터로 촘촘하고 세밀하게 훑어냅니다.
③ 비선형성의 증가 (Non-linearity)
이것이 핵심입니다. $5 \times 5$ 필터를 쓰면 ReLU(활성화 함수)를 한 번만 거치지만, $3 \times 3$을 두 번 쓰면 ReLU를 두 번 거칩니다. 층이 많아질수록 결정 경계(Decision Boundary)가 더 비선형적으로 변하여, 모델이 훨씬 더 복잡하고 미묘한 데이터의 패턴을 학습할 수 있게 됩니다.
히든 카드: 1x1 Convolution의 마법
VGG16의 일부 버전과 이후 등장한 ResNet, GoogLeNet에서 핵심적으로 사용되는 것이 바로 $1 \times 1$ 필터입니다. "가로세로 1픽셀짜리 필터가 무슨 의미가 있지?"라고 생각할 수 있지만, 이는 신의 한 수였습니다.
핵심 기능 1: 채널 수 조절 (Dimension Reduction)
이미지의 가로, 세로 크기는 그대로 둔 채 채널(깊이)의 개수만 내 마음대로 줄이거나 늘릴 수 있습니다. 채널이 너무 많아 연산량이 부담될 때, $1 \times 1$ Conv로 채널을 압축(Bottleneck 구조)하여 연산 효율을 극대화합니다.
핵심 기능 2: 비선형성 추가
$1 \times 1$ 필터를 통과한 후에도 ReLU를 거칩니다. 즉, 이미지의 공간적 특징은 건드리지 않으면서 층을 한 단계 더 쌓는 효과를 주어 모델의 학습 능력을 높입니다.
핵심 기능 3: 특성 맵의 연산 (Feature Combination)
여러 개의 채널에 흩어져 있는 정보들을 $1 \times 1$ 연산을 통해 적절히 혼합(Mixing)하여 새로운 특징을 만들어냅니다.
3x3 vs 1x1: CNN의 두 핵심 병기의 비교
VGG16이 $3 \times 3$ 필터로 "깊이"의 효율성을 증명했다면, 이후 모델들은 $1 \times 1$ 필터를 섞어 쓰며 "효율의 극치"를 달성했습니다. 이 두 필터는 서로 역할이 완전히 다릅니다.
3x3 필터: "공간(Space)의 마법사"
- 주 역할: 주변 픽셀들과의 관계를 파악합니다.
- 특징: 상하좌우 픽셀을 함께 보기 때문에 이미지의 공간적인 특징(Spatial Features) 즉, 선, 면, 형태 등을 추출하는 데 최적화되어 있습니다.
- 한계: 필터가 움직일 때마다 $3 \times 3 = 9$배의 연산이 필요하므로, 채널이 많아지면 연산량이 급격히 늘어납니다.
1x1 필터: "채널(Channel)의 지휘자"
- 주 역할: 공간적 특징은 유지한 채, 채널 방향의 정보만 압축하거나 확장합니다.
- 특징: 가로세로 $1 \times 1$ 크기이므로 주변 픽셀은 보지 않습니다. 오직 한 픽셀 위치에서 깊이 방향(Channel)으로만 가중치를 곱합니다.
- 핵심 이점 (연산량 다이어트):
- $3 \times 3$ 연산을 하기 전, $1 \times 1$로 채널 수를 미리 확 줄여버리면 전체 연산량이 드라마틱하게 감소합니다. (이것이 GoogLeNet의 인셉션 모듈과 ResNet의 Bottleneck 구조의 핵심입니다.)
한눈에 비교하는 요약 테이블
비교 항목 3 x 3 Convolution 1 x 1 Convolution 주요 목적 공간적 패턴(형태, 질감) 추출 채널 간 정보 통합 및 차원 조절 공간 정보 주변 픽셀 관계 학습 (Receptive Field 확장) 변화 없음 (위치 정보 유지) 차원(채널) 조절 가능하지만 연산량 부담이 큼 매우 효율적으로 조절 (차원 축소/확장) 주요 이점 더 넓은 영역을 추상화함 연산량 감소, 비선형성(ReLU) 추가 비유 돋보기를 들고 그림 전체를 훑는 과정 여러 겹의 색종이를 한 장으로 압축하는 과정 정리하며
특징 AlexNet VGG16 핵심 철학 GPU 성능을 활용한 깊은 구조의 시작 "작은 필터($3 \times 3$)를 깊게 쌓자" 필터 크기 $11 \times 11$, $5 \times 5$, $3 \times 3$ 혼용 $3 \times 3$ 고정 파라미터 상대적으로 비효율적 연산량은 많으나 파라미터 활용 최적화 비선형성 낮음 매우 높음 (ReLU 반복 사용) 결론적으로, 이미지 인식 모델의 발전은 단순히 층을 쌓는 것을 넘어 "어떻게 하면 파라미터를 아끼면서도 비선형성을 극대화하여 추상적인 특징을 잘 뽑아낼 것인가"의 고민 과정이었습니다. VGG16은 그 해답이 '작은 필터의 반복'에 있음을 증명했고, 이는 현대 딥러닝 아키텍처의 표준이 되었습니다.
'AI' 카테고리의 다른 글
Segmentation부터 DSLR의 이해 (0) 2026.02.10 사전학습(Pre-training)의 핵심 (0) 2026.02.06 ResNet(Residual Network)의 깊이 있는 이해 (1) 2026.02.05 클래스 활성화 맵(Class Activation Map, CAM) (0) 2026.02.04 CNN 필터는 어떻게 '스스로' 진화하는가? (역전파와 두 가지 가중치) (0) 2026.02.04